Watch all the Transform 2020 sessions on-demand here.
Google subsidiary DeepMind today unveiled a new type of computer vision algorithm that can generate 3D models of a scene from 2D snapshots: the Generative Query Network (GQN).
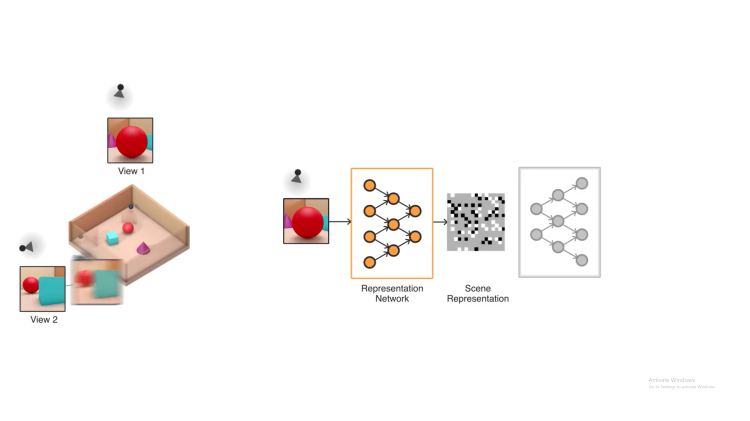
The GQN, details of which were published in Science, can “imagine” and render scenes from any angle without any human supervision or training. Given just a handful of pictures of a scene — a wallpapered room with a colored sphere on the floor, for example — the algorithm can render opposite, unseen sides of objects and generate a 3D view from multiple vantage points, even accounting for things like lighting in shadows.
It aims to replicate the way the human brain learns about its surroundings and the physical interactions between objects, and eliminate the need for AI researchers to annotate images in datasets. Most visual recognition systems require a human to label every aspect of every object in each scene in a dataset, a laborious and costly process.
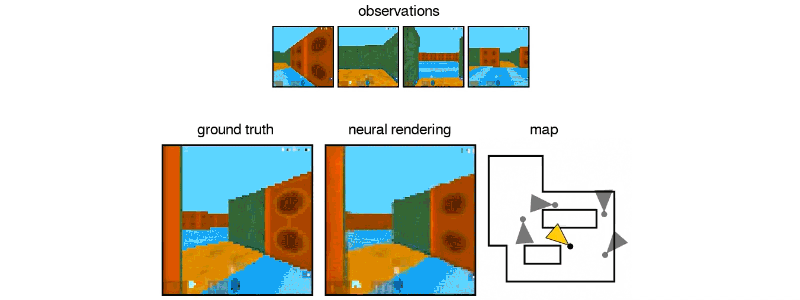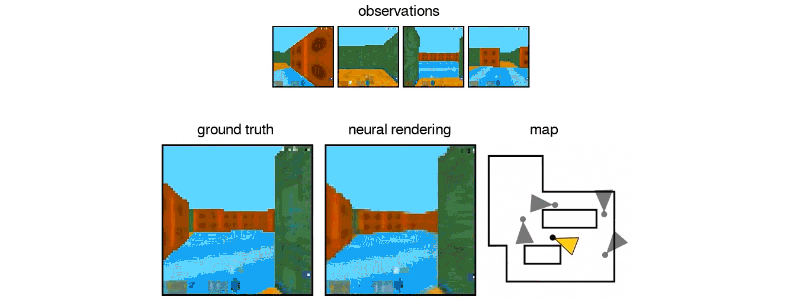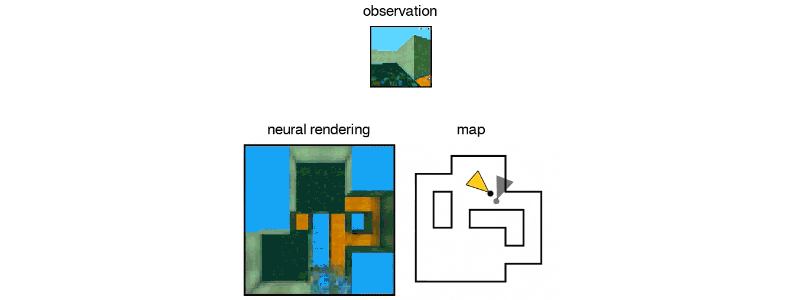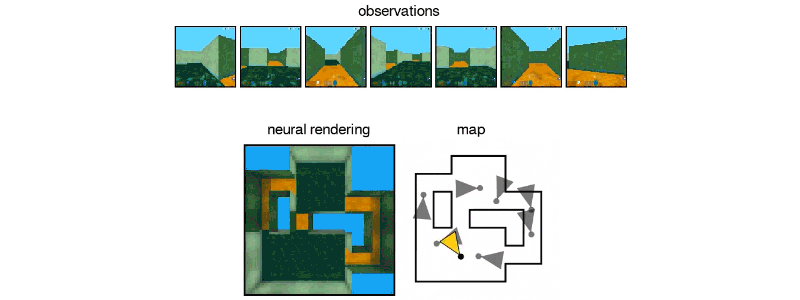
Above: DeepMind’s GQN imagined this maze from static images.
“Much like infants and animals, the GQN learns by trying to make sense of its observations of the world around it,” DeepMind researchers wrote in a blog post. “In doing so, the GQN learns about plausible scenes and their geometrical properties, without any human labeling of the contents of scenes … [T]he GQN learns about plausible scenes and their geometrical properties … without any human labeling of the contents of scenes.”
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
The two-part system is made up of a representation network and a generation network. The former takes input data and translates it into a mathematical representation (a vector) describing the scene, and the latter images the scene.
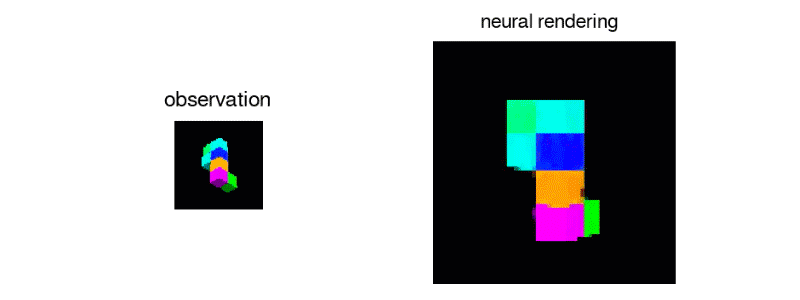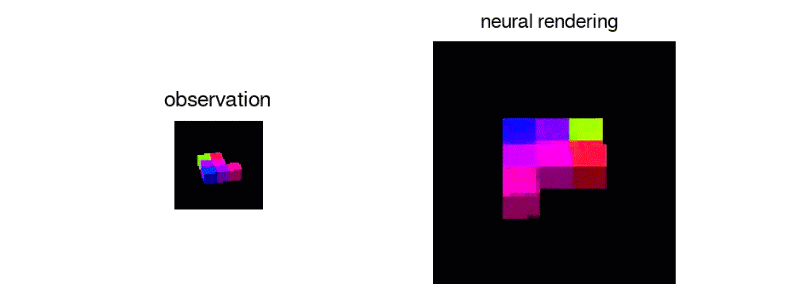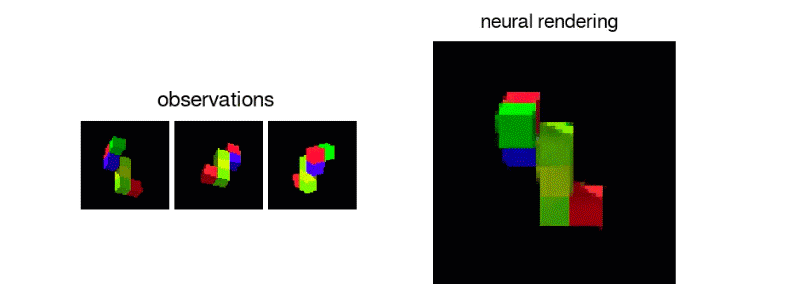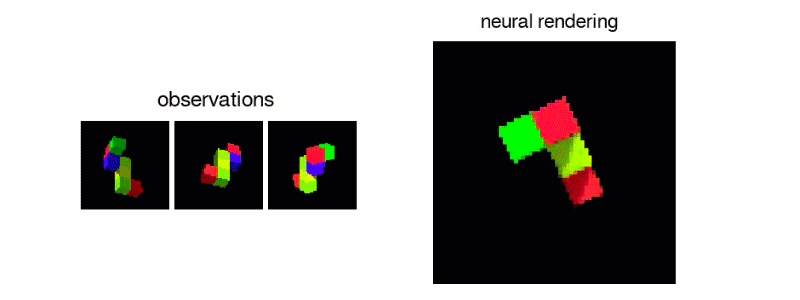
Above: The GQN creating a manipulable virtual object from 2D sample data.
To train the system, DeepMind researchers fed GQN images of scenes from different angles, which it used to teach itself about the textures, colors, and lighting of objects independently of one another and the spatial relationships between them. It then predicted what those objects would look like off to the side or from behind.
Using its spatial understanding, the GQN could control the objects (by using a virtual robot arm, for example, to pick up a ball). And it self-corrects as it moves around the scene, adjusting its predictions when they prove incorrect.
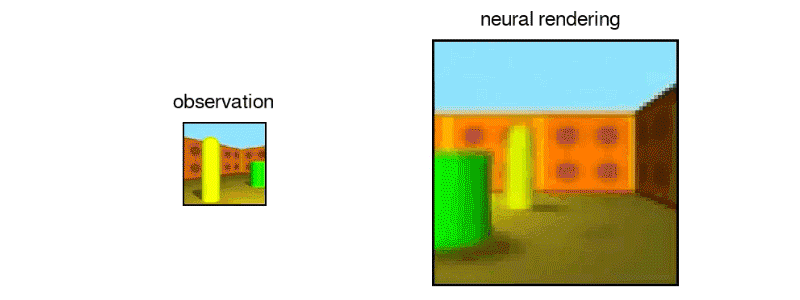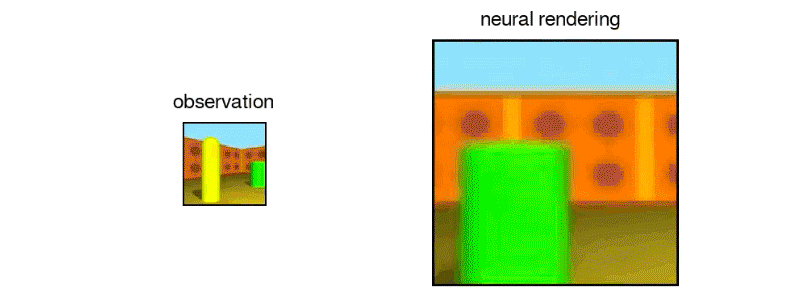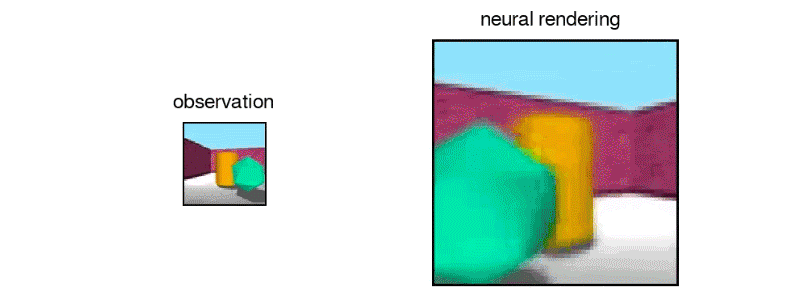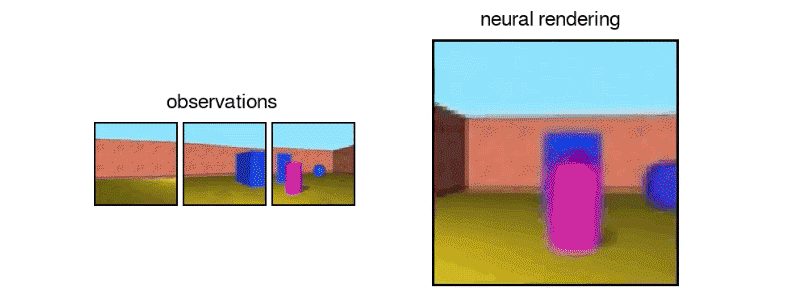
Above: Another 3D maze imagined by the GQN.
The GQN isn’t without limitations — it’s only been tested on simple scenes containing a small number of objects, and it’s not sophisticated enough to generate complex 3D models. But DeepMind is developing more robust systems that require less processing power and a smaller corpus, as well as frameworks that can process higher-resolution images.
“While there is still much more research to be done before our approach is ready to be deployed in practice, we believe this work is a sizeable step towards fully autonomous scene understanding,” the researchers wrote.

