
testsetset
Apps that detect objects, classify images, and recognize faces are nothing new in the world of smartphones; they’ve been popularized by apps like Google Lens and Snapchat, to name a few. But ubiquity is no substitute for quality, and the underlying machine learning models most use — convolutional neural networks — tend to suffer from either slowness or inaccuracy. It’s a computational trade-off forced by hardware constraints.
There’s hope on the horizon, though. Researchers at Google have developed an approach to artificial intelligence (AI) model selection that achieves record speed and precision.
In a new paper (“MnasNet: Platform-Aware Neural Architecture Search for Mobile“) and blog post, the team describes an automated system, MnasNet, that identifies ideal neural architectures from a list of candidates, incorporating reinforcement learning to account for mobile speed constraints. It executes various models on a particular device — Google’s Pixel, in this study — and measures their real-world performance, automatically selecting the best out of the bunch.
“In this way, we can directly measure what is achievable in real-world practice,” the researchers wrote in the blog post, “given that each type of mobile devices has its own software and hardware idiosyncrasies and may require different architectures for the best trade-offs between accuracy and speed.”
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
The system consists of three parts: (1) a recurrent neural network-powered controller that learns and samples the models’ architectures, (2) a trainer that builds and trains the models, and (3) a TensorFlow Lite-powered inference engine that measures the models’ speeds.
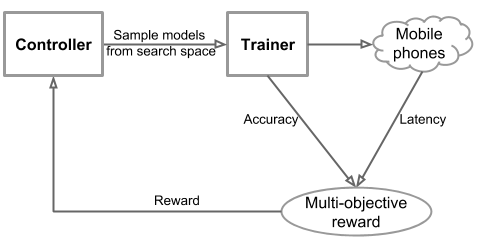
Above: A diagram illustrating the components of Google’s system.
The team tested its top-pick models on ImageNet, an image database maintained by Stanford and Princeton, and on the Common Objects in Context (COCO) object recognition dataset. The results showed that the models ran 1.5 times faster than state-of-the-art mobile model MobileNetV2, and 2.4 times faster than NASNet, a neural architecture search system. On COCO, meanwhile, Google’s models achieved both “higher accuracy and higher speed” over MobileNet, with 35 times less computation cost compared to the SSD300 model, the researchers’ benchmark.
“We are pleased to see that our automated approach can achieve state-of-the-art performance on multiple complex mobile vision tasks,” the team wrote. “In future, we plan to incorporate more operations and optimizations into our search space, and apply it to more mobile vision tasks such as semantic segmentation.”
The research comes as edge and offline (as opposed to cloud-hosted) AI gain steam — particularly in the mobile arena. During its 2018 Worldwide Developers Conference in June, Apple introduced an improved version of ML Core, its on-device machine learning framework for iOS. And at Google I/O 2018, Google announced ML Kit, a software development kit that includes tools that make it easier to deploy custom TensorFlow Lite models in apps.

