
Watch all the Transform 2020 sessions on-demand here.
If you’re a Google Cloud customer who’s tapping into the company’s artificially intelligent (AI) suite for text-to-speech or speech-to-text services, good news: New features are headed your way. The Mountain View company today announced significant updates on those fronts, including the general availability of Cloud Text-to-Speech, new audio profiles that optimize sound for playback on different devices, enhancements to multichannel recognition, and more.
First on the list: improved speech synthesis in Google’s Cloud Text-to-Speech. Starting this week, it’ll offer multilingual access to voices generated using WaveNet, a machine learning technique developed by Alphabet subsidiary DeepMind. Without diving too deep into the weeds, it mimics things like stress and intonation in speech — sounds referred to in linguistics as prosody — by identifying tonal patterns. In addition to producing much more convincing voice snippets than previous models, it’s also more efficient — running on Google’s Cloud TPU hardware, WaveNet can generate a one-second sample in just 50 milliseconds.
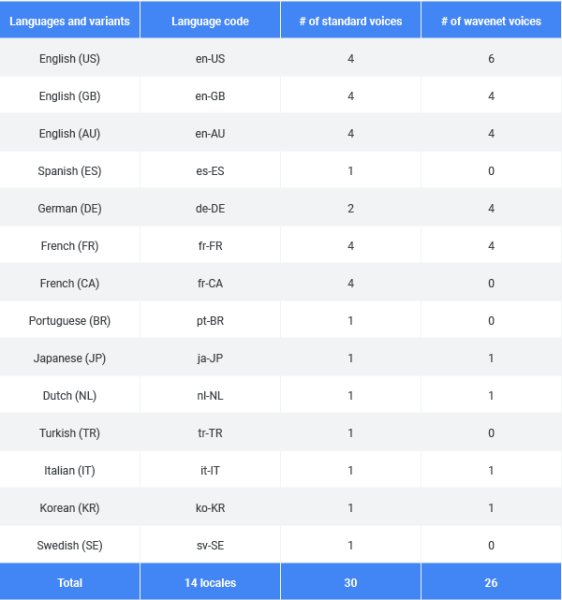
Cloud Text-to-Speech now offers 17 new WaveNet voices and supports 14 languages and variants. In total, it’s got 56 total voices: 30 standard voices and 26 WaveNet voices on offer. (Check out this webpage for the full list.)
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
Expanded WaveNet support isn’t the only new feature on tap for Cloud Text-to-Speech customers. Audio profiles, which were previously available in beta, are launching broadly today.
In a nutshell, audio profiles let you optimize the speech produced by Cloud Text-to-Speech’s APIs for playback on different types of hardware. You can create a profile for wearable devices with smaller speakers, for example, or one specifically for cars speakers and headphones. It’s particularly handy for devices that don’t support specific frequencies; Cloud Text-to-Speech can automatically shift out-of-range audio to within hearing range, enhancing its clarity.

Above: A graphic illustrating how Cloud Text-to-Speech’s Audio Profiles work in practice.
“The physical properties of each device, as well as the environment they are placed in, influence the range of frequencies and level of detail they produce (e.g., bass, treble and volume),” the Google Cloud team wrote in a blog post. “The … audio sample [resulting from Audio Profiles] might actually sound worse than the original sample on laptop speakers, but will sound better on a phone line.”
Eight device profiles are supported at launch:
- Wearables (e.g., Wear OS devices)
- Handsets
- Headphones
- Small Bluetooth speakers (Google Home mini)
- Medium Bluetooth speakers (Google Home)
- Home entertainment systems (Google Home Max)
- Car speakers
- Interactive voice response (IVR) systems
Here’s the handset profile:
And here’s the phone profile:
Speech-to-Text updates
Google announced a handful of new Cloud Speech-to-Text features at its Google Cloud Next developer conference in July, and today shed additional light on three of them: multichannel recognition, language auto-detect, and word-level confidence.
Multi-channel recognition offers an easy way to transcribe multiple channels of audio by automatically denoting the separate channels for each word. (Google notes that achieving the best transcription quality often requires the use of several channels.) And for audio samples that aren’t recorded separately, Cloud Speech-to-Text offers diarization, which uses machine learning to tag each word with an identifying speaker number. The accuracy of the tags improve over time, Google said.

Above: Google’s Cloud Speech-to-Text diarization feature in action.
That’s all well and fine, but what if you’re a developer with lots of bilingual users? Enter language auto-detect, which lets you send up to four language codes at once in queries to Cloud Speech-to-Text. The API will automatically determine which language was spoken and return a transcript, much like how the Google Assistant detects languages and responds in kind. (Users also get the choice of selecting a language manually.)
Last but not least on the Cloud Speech-to-Text front is word-level confidence, which offers developers fine-grained control over Google’s speech recognition engine. If you so choose, you can tie confidence scores to triggers within apps — like a prompt that encourages the user to repeat themselves if they mumble or speak too softly, for instance.
Google elaborated:
For example, if a user inputs “please setup a meeting with John for tomorrow at 2PM” into your app, you can decide to prompt the user to repeat “John” or “2PM,” if either have low confidence, but not to reprompt for “please” even if has low confidence since it’s not critical to that particular sentence.
Multi-channel recognition, language auto-detect, and word-level confidence are available today.

