Watch all the Transform 2020 sessions on-demand here.
Apple doesn’t generally let its employees blog, but its Machine Learning Journal is an exception, spotlighting the quiet labors and current projects of its ML research teams. The latest entry previews potential future improvements to Apple’s QuickType predictive keyboard, based on a major challenge: teaching a machine to use all of a document’s content to guess what word someone will type next.
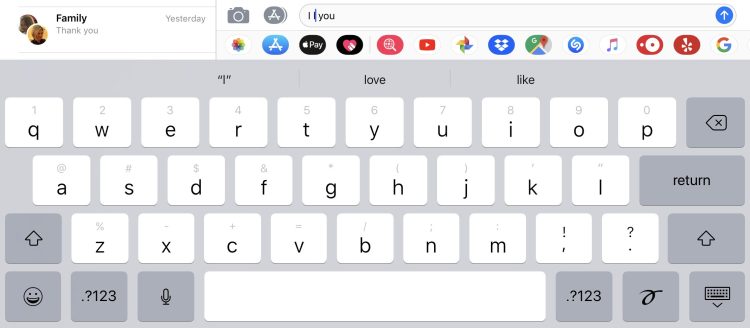
Currently, the predictive keyboard uses a combination of narrow, local context and your typing input to guess what’s coming next. For example, if you started typing a word beginning with “L” between “I” and “you,” it might reasonably guess “love.”
Apple’s Frameworks Natural Language Processing Team notes that additional context — “global semantic context” — can yield better results. Looking at the entirety of a document to figure out what’s being said might increase the likelihood that “love” has nothing to do with the document and that the typist might be adding the words “listen to” instead.
Actually pulling off full-document processing isn’t easy, though, and Apple’s exploring deep learning via neural networks as a potential solution. A prototype system can look at all the context to the left and right of a given word, analyzing and scoring each portion of the text for potential relevance. It uses machine training catalogs of 10 million to 5 billion words, though researchers found that the smallest catalog worked as well as the largest for this purpose.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
The project is currently uncompleted, as Apple needs to continue teaching its machines to learn how to process words and phrases within the larger global context, but it’s making progress. Going forward, Apple expects that both local and global context will be used in predicting text input — and if it succeeds, machines could become much better at guessing our next thoughts from what we’ve already said.

