
Watch all the Transform 2020 sessions on-demand here.
Searching for PDFs or images by their file names is a torturous exercise, particularly if those file names aren’t descriptive. But if you’re a Dropbox user, good news: It’s about to get easier.
The San Francisco cloud storage company today announced Auto OCR, a machine learning-powered optical character recognition (OCR) engine that automatically extracts and indexes text from pics and PDFs — including the 24 billion already stored across Dropbox’s more than 500 million user accounts. It’s the most computationally intensive project its machine learning team has ever undertaken, Dropbox said.
“Finding the [image or PDF] you need — especially if there are tens of thousands stored or shared with you in Dropbox — is tough,” it wrote in a blog post. “This new feature harnesses the power of our machine intelligence capabilities to make search smarter for you.”
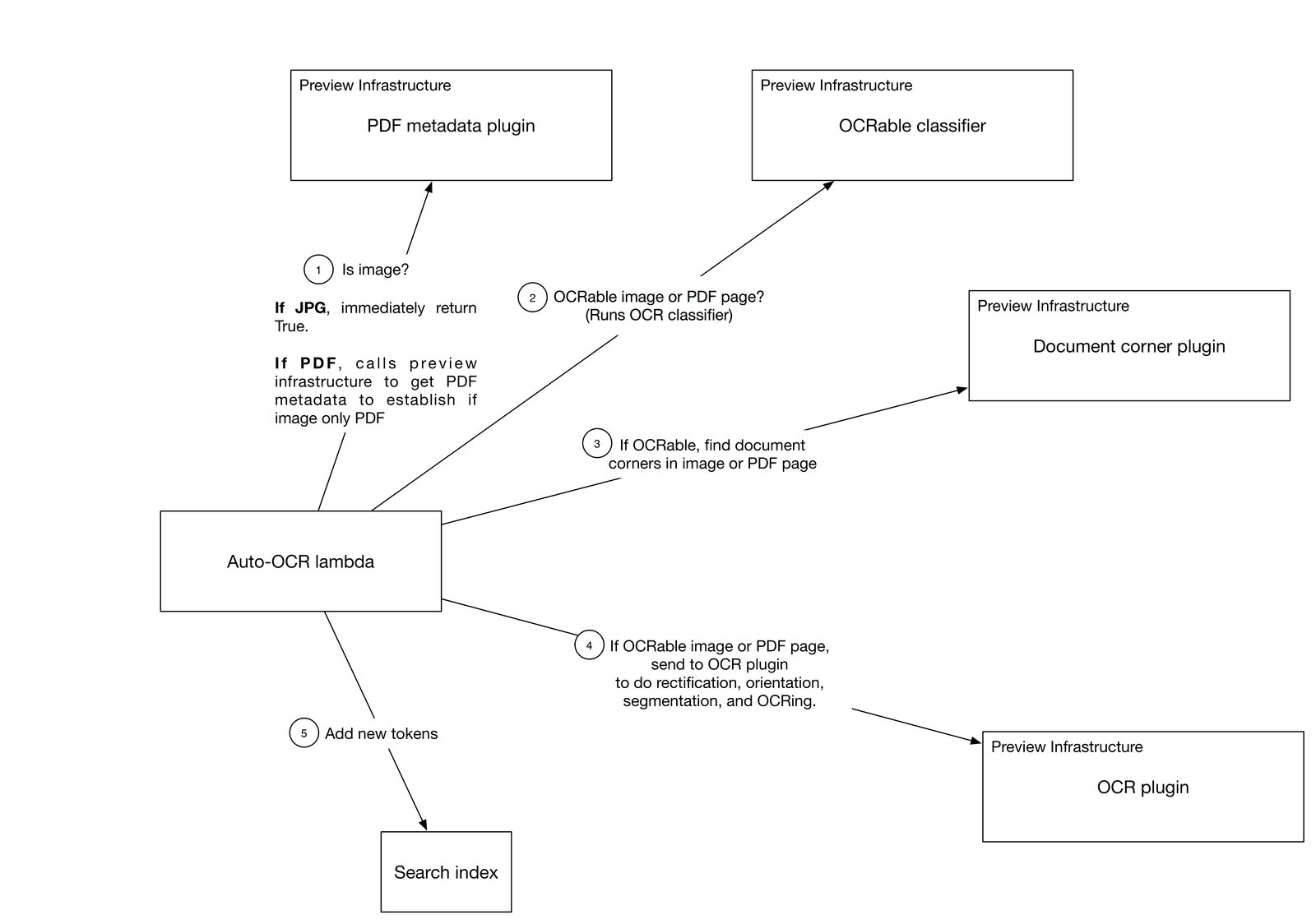
Above: The complete auto OCR pipeline.
Auto OCR works more or less as you’d expect. If the document you’re looking for contains unique titles, names, addresses, or strings of characters, pecking them out within Dropbox’s search bar on the web, desktop, or mobile (Android or iOS) will bubble relevant files to the top of results. At launch, most new and previously uploaded JPEGs, GIFs, PNGs, TIFFs, and PDFs will be indexed in full.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
“Looking for a contract that a teammate scanned years ago? Just search for the vendor,” Dropbox wrote. “Trying to track down blueprints an architect put together for your remodel? Type in their name. Can’t remember where you saved that flight itinerary screenshot? Enter in the destination airport.”
Auto OCR is an English-only affair for now, and you’ll have to sign up for one of three premium plans — Dropbox Professional ($12.50 per user a month), Business Advance ($20 per user a month), or Enterprise — to take advantage. Starting this week, Dropbox Business Advanced and Enterprise admins can switch on auto OCR through the admin console.
Behind the scenes
Auto OCR is a part of the Dropbox intelligence initiative (DBXi), Dropbox’s eponymous effort to “weave … [AI]” into all of its products and services.
OCR isn’t particularly novel in the realm of cloud storage; Microsoft’s OneDrive can search text inside documents, as can Google Drive. But be that as it may, designing a system that can scale across hundreds of millions of documents and images is no walk in the park, according to Dropbox machine learning engineer Leonard Fink.
“The types of files we want to process are those that currently don’t have indexable text content,” Fink wrote in a blog post. “This includes image formats and PDF files without text data. However, not all images or PDFs contain text; in fact, [9 percent of JPEGs] are just photos or illustrations without any text.”
PDFs present a particular challenge. The average doc in Dropbox has 8.8 pages, according to Fink, and would contribute over 10 times as much processing overhead as JPEGs if the files weren’t in some way prioritized.
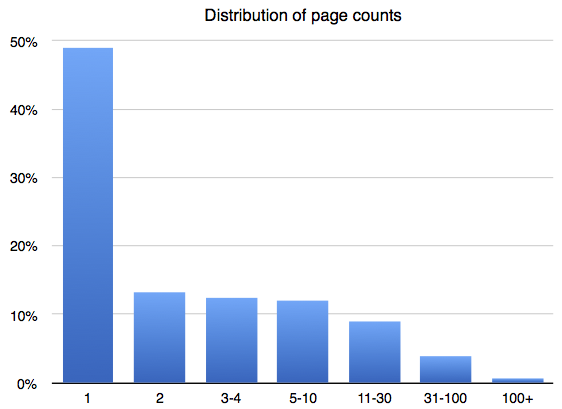
Above: A histogram of PDF page counts across Dropbox.
The Dropbox team’s solution is to divide them into one of three buckets — PDFs with text that’s already embedded and indexable, PDFs with text in the form of an image, and PDFs without substantial text — and cap the number of indexed pages at 10. (Fink notes that half of PDFs in Dropbox have one page, and that 90 percent have 10 pages or fewer.)
To extract words from the PDFs, auto OCR renders entire pages to raster data using a server-side component built on PDFium, the renderer in Google’s open source Chromium project (and the foundation for the Chrome browser). It’s the same system Dropbox uses to generate preview thumbnails of PDFs, and to detect body text within a PDF.
A TensorFlow model trained on several thousand images gathered from public sources, users, and Dropbox employees determines which files are optimal candidates for text extraction, and a second AI model — a modified Densenet-121 deep convolutional network trained on the open source ImageNet dataset — detects the corners of the docs in images. Meanwhile, yet another model extracts “tokens” from files that roughly correspond to words, which it arranges in lists and adds to Dropbox’s search index.
A micro-service worker — lambda — created with Cape, Dropbox’s in-house, large-scale framework for asynchronous event-stream processing, kick-starts the auto OCR pipeline whenever a file’s uploaded or edited. To increase the system’s robustness, the Dropbox team implemented a “retry” logic that makes consecutive attempts to parse a PDF or image in the event of an error. (It resulted in an 88 percent reduction in failure rate for PDF metadata extraction, according to Fink.)
“Making document images searchable is the first step towards a deeper understanding of the structure and content of documents,” Fink wrote. “With that information, Dropbox can help users organize their files better — a step on the road to a more enlightened way of working.”
The months since the kickoff of DBXi and Dropbox’s initial public offering have seen an uptick in AI-powered product deployments.
Last week marked the launch of Nautilus, an overhauled search engine that uses machine learning to rank documents in search results. And in September, Dropbox detailed an experimental AI-powered desktop notifications feature that intelligently highlights “the most important [files]” connected to accounts.
Both came on the heels of a partnership with Google that will let users of its G Suite productivity service keep Docs, Sheets, and Slides file inside Dropbox’s cloud storage environment by the end of this year, and the rollout of expanded base storage for paid tiers.
“We see tremendous potential to use machine intelligence to improve the work experience itself,” Dropbox product group managers Timo Mertens and Vinod Valloppillil wrote in a blog post earlier this year. “From a technical perspective, these are important problems to solve, and success means not only intuitive user interfaces, but also lightning-fast response times, industry-leading prediction, and the highest standards for maintaining data privacy.”

