
Watch all the Transform 2020 sessions on-demand here.
Chatbots rarely make great conversationalists. With the exception of perhaps Microsoft’s Xiaoice in China, which has about 40 million users and averages 23 back-and-forth exchanges, and Alibaba’s Dian Xiaomi, an automated sales agent that serves nearly 3.5 million customers a day, most can’t hold humans’ attention for much longer than 15 minutes. But that’s not tempering bot adoption any — in fact, Gartner predicts that they’ll power 85 percent of all customer service interactions by the year 2020.
Fortunately, continued advances in the field of AI research promise to make conversant AI much more sophisticated by then. In a paper published this week on the preprint paper Arxiv.org (“Learning from Dialogue after Deployment: Feed Yourself, Chatbot!“), scientists from Facebook’s AI Research and Stanford University describe a chatbot that can self-improve by extracting training data from conversations.
“When the conversation appears to be going well, the user’s responses become new training examples to imitate,” the paper’s authors explained. “[And] when the agent believes it has made a mistake, it asks for feedback; learning to predict the feedback that will be given improves the chatbot’s dialogue abilities further … These new examples improve the agent’s dialogue abilities while using only natural responses from the user that do not require special structure, accompanying numerical feedback, or additional human intervention in order to be used.”
Such an AI system could continuously adapt without much in the way of human supervision, the researchers posit. The only problem? Letting a chatbot train on its own conversations runs the risk of reinforcing errors, leading to “absurd” conversations.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
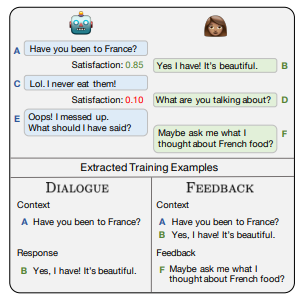
Above: A typical exchange between the researchers’ proposed chatbot and a human partner.
In the researchers’ case, the solution turned out to be satisfaction — that is to say, a chat partner’s satisfaction with the bot’s responses. They collected a “satisfaction” dataset by having contract workers chitchat with the AI agent and assign a rating between 1 and 5 for the quality of each of its responses, which were used to “teach” the system to predict “satisfied” and “unsatisfied” human replies to its utterances. (Contexts that were rated 2 were discarded in order to increase the separation between classes for “a cleaner training set.”)
In production, as the chatbot and a human exchanged words, the former trained on two tasks simultaneously: dialog (what it’s going to say next) and feedback (the coherency of its replies). For each turn, it took into account prior exchanges, which it used to generate its next reply and a numerical satisfaction score from 0 to 1. If satisfaction reached a certain threshold, it extracted training data using the previous context and the human’s response. But if the score was low, the bot requested feedback with a question, and used the response to create a new example for the feedback task.
For the sake of example, say the chatbot responded to the question “How’s the weather in France this time of year?” with a non-sequitur like “It’s delicious.” Most any rational chat partner would probably follow up with: “What the heck are you talking about?” From their tone, the bot might deduce that they’re unsatisfied and, as it’s designed to do, politely prompt them to correct it (“Oops! I messed up. What should I have said?”). Once they fed it the right answer (“Maybe you should have told me that it’s cold.”), it would extract training examples to prevent it from making the same mistake in the future.
In the course of their research, the scientists fed the chatbot — which was built on the Transformer, a neural architecture capable of outperforming state-of-the-art models in language translation tasks — 131,438 “human-human” dialogue examples sourced from PersonaChat, a publicly available dataset consisting of short dialogs between crowdworkers instructed to “chat with the other person … and try to get to know each other.” In tests, they found that, given small training sets where the learning curve was the steepest, its overall accuracy increased by 31 percent compared to the baseline, with the best-performing model achieving 46.3 percent accuracy and 68.4 percent accuracy on the dialog task and feedback tasks, respectively.
As for the chatbot’s ability to predict user satisfaction, it “significantly outperform[ed]” prior methods, even with only 1,000 training examples.
“We show that dialogue ability improves by imitating human responses when the human is satisfied, or by asking for feedback when they are not, predicting it as an auxiliary task,” the researchers wrote. “[A]nd we demonstrate that classifying user satisfaction is a learnable task important for the self-feeding process, significantly outperforming an approach based on model uncertainty.”
The datasets, models, and training code described in the paper will be made available through Facebook’s ParlAI platform, they said. With any luck, perhaps they’ll help make the next generation of chatbots actually worth talking to.

