
Watch all the Transform 2020 sessions on-demand here.
Want to dive earnestly into artificial intelligence (AI) development, but find the programming piece of it intimidating? Not to worry — Uber has your back. The ride-hailing giant today debuted Ludwig, an open source “toolbox” built on top of Google’s TensorFlow framework that allows users to train and test AI models without having to write code.
Uber says Ludwig is the culmination of two years’ worth of work to streamline the deployment of AI systems in applied projects and says it has been tapping the tool suite internally for tasks like extracting information from driver licenses, identifying points of interest during conversations between driver-partners and riders, predicting food delivery times, and more.
“Ludwig is unique in its ability to help make deep learning easier to understand for non-experts and enable faster model improvement iteration cycles for experienced machine learning developers and researchers alike,” Uber wrote in a blog post. “By using Ludwig, experts and researchers can simplify the prototyping process and streamline data processing so that they can focus on developing deep learning architectures rather than data wrangling.”
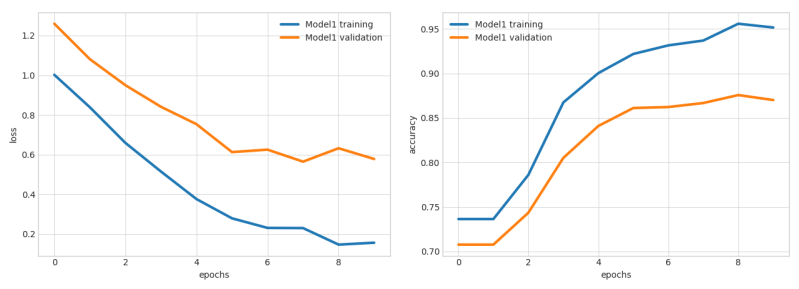
Above: Visualizations produced by Ludwig.
As Uber explains, Ludwig provides a set of AI architectures that can be combined to create an end-to-end model for a given use case. Kicking off training requires no more than a tabular dataset file (like CSV) and a YAML configuration file that specifies which columns of the former are input features (i.e., the individual properties or phenomenon being observed) and which are output target variables. If more than one output target variable is specified, Ludwig learns to predict all the outputs simultaneously.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
New model definitions can contain additional information, including preprocessing data for each feature in the dataset and model training parameters. And models trained in Ludwig are saved and can be loaded at a later time to obtain predictions on new data.
Novelly, for each data type Ludwig supports, the toolset offers data type-specific encoders that map the raw data to tensors (data structures used in linear algebra), along with decoders that map tensors to the raw data. Built-in combiners automatically piece together the tensors from all input encoders, process them, and return them to be used for the output decoders.
“By composing these data type-specific components, users can make Ludwig train models on a wide variety of tasks,” Uber wrote. “For example, by combining a text encoder and a category decoder, the user can obtain a text classifier, while combining an image encoder and a text decoder will enable the user to obtain an image captioning model … This versatile and flexible encoder-decoder architecture makes it easy for less experienced deep learning practitioners to train models for diverse machine learning tasks, such as text classification, object classification, image captioning, sequence tagging, regression, language modeling, machine translation, time series forecasting, and question answering.”
Additionally, Ludwig provides a set of command line utilities for training, testing models, and obtaining predictions; tools for evaluating models and comparing their predictions through visualizations; and a Python programmatic API that lets users train or load a model and use it to obtain predictions on new data. Moreover, Ludwig’s capable of distributed model training through the use of Uber’s Horovod, a framework that enables support for multiple graphics cards and machines.
Currently, Ludwig contains encoders and decoders for binary values, float numbers, categories, discrete sequences, sets, bags, images, text, and time series, and it supports select pretrained models. In the future, Uber plans to add new encoders for data types for text, images, audio, point clouds, and graphs and to integrate “more scalable solutions” for managing big datasets.
“We decided to open-source Ludwig because we believe that it can be a useful tool for non-expert machine learning practitioners and experienced deep learning developers and researchers alike. The non-experts can quickly train and test deep learning models without having to write code. Experts can obtain strong baselines to compare their models against and have an experimentation setting that makes it easy to test new ideas and analyze models by performing standard data preprocessing and visualization.”
Ludwig’s debut follows the release of Uber’s Pyro in 2017, a deep probabilistic programming language built on Facebook’s PyTorch machine learning framework. And it comes as no-code AI development tools — like Baidu’s EZDL and Microsoft’s AI model builder — continue to gain steam.

