
Watch all the Transform 2020 sessions on-demand here.
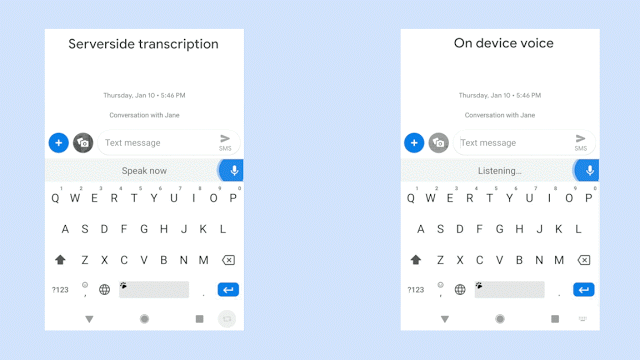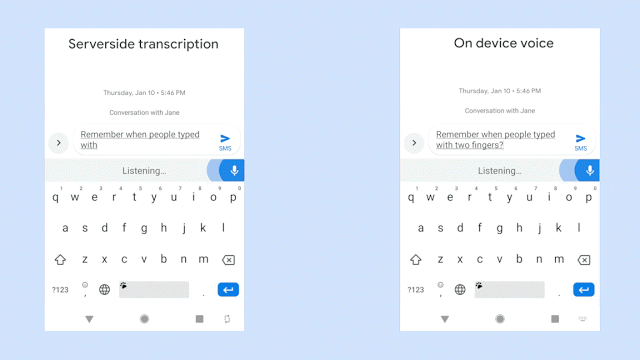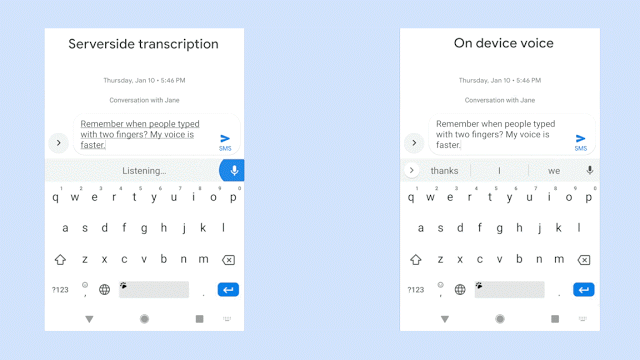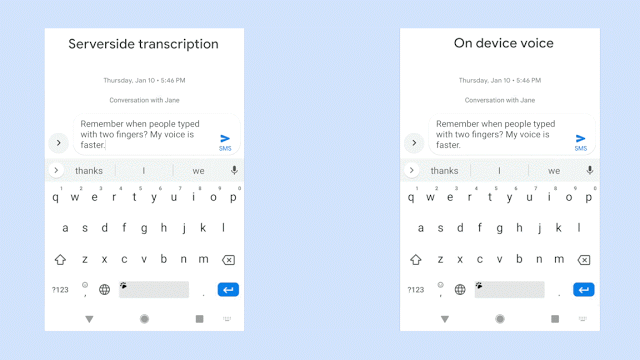
On-device machine learning algorithms afford plenty of advantages, namely low latency and availability — because processing is performed locally as opposed to remotely on a server, connectivity has no bearing on performance. Google sees the wisdom in this: It today announced that Gboard, its cross-platform virtual keyboard app, now uses an end-to-end recognizer to power American English speech input on Pixel smartphones.
“This means no more network latency or spottiness — the new recognizer is always available, even when you are offline,” Johan Schalkwyk, a fellow on Google’s Speech Team, wrote in a blog post. “The model works at the character level, so that as you speak, it outputs words character-by-character, just as if someone was typing out what you say in real-time, and exactly as you’d expect from a keyboard dictation system.”
It’s more complicated than it sounds. As Schalkwyk explains, speech recognition systems of old consisted of several independently optimized components: an acoustic model that maps short segments of audio to phonemes — perceptually distinct units of sound (for example, p and d in the English word “pad”) — and a language model that expresses the likelihood of given phrases. Around 2014, though, a new “sequence-to-sequence” paradigm took hold: single neural networks capable of directly mapping input audio waveform to an output sentence. These laid the foundation for more sophisticated systems with state-of-the-art accuracy, but with a key limitation: an architectural inability to support real-time voice transcription.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
By contrast, Gboard’s new model — a recurrent neural network transducer (RNN-T) trained on second-generation tensor processing units (TPU) in Google Cloud — can handle real-time transcription, thanks to its ability to process input sequences (utterances) and produce outputs (the sentence) continuously. It recognizes spoken characters one-by-one, using a feedback loop that feeds symbols predicted by the model back into said model to predict the next symbols. And as the result of a newly devised training technique, it’s five percent less likely to mistake words during transcription, Google says.
The trained RNN-T was quite small to begin with — only 450MB — but Schalkwyk and colleagues sought to shrink it further. This proved to be a challenge: Speech recognition engines compose acoustic, pronunciation, and language models together in decoder graphs that can span multiple gigabytes. However, using quantization and other techniques, the Speech Team managed to achieve four times compression (to 80MB) and four times speedup at runtime, enabling the deployed model to run “faster than real-time speech” on a single processor core.
“Given the trends in the industry, with the convergence of specialized hardware and algorithmic improvements, we are hopeful that the techniques presented here can soon be adopted in more languages and across broader domains of application,” Schalkwyk said.

