
Watch all the Transform 2020 sessions on-demand here.
Flex Logix Technologies revealed it has developed a new coprocessor for edge AI processing: the InferX X1.
The new chip is based on patented interconnect technology from its embedded field-programmable gate array (eFPGA) chip designs. It combines the eFPGA tech with inference-optimized nnMAX clusters in the new combination chip.
The Mountain View, California-based company said its first chip design (beyond its usual chip technology licensing business) will deliver near-datacenter throughput at a fraction of the power and cost of rivals. Flex Logix claims it delivers up to 10 times the throughput of existing inferencing edge chips.
The new chip would likely be used for edge gateways, low-end servers, robotics, and other high-performance edge devices. Flex Logix revealed the chip in a presentation at the Linley Processor Conference in Santa Clara, California.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
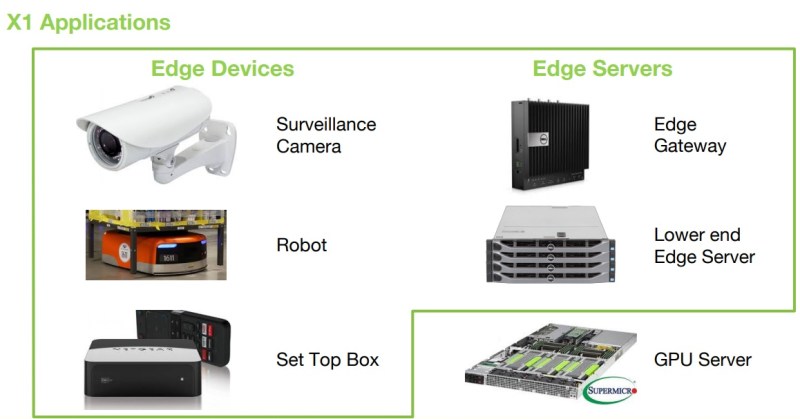
Above: Possible applications for Flex Logix coprocessor.
The Flex Logix InferX X1 chip delivers high throughput in edge applications with a single DRAM (dynamic random access memory chip). The company claims much higher throughput per watt than existing solutions, with the chip’s performance advantage especially strong at low batch sizes, which are required in edge applications where there is typically only one camera or sensor.
InferX X1’s performance at small batch sizes is close to datacenter inference boards and is optimized for large models that need hundreds of billions of operations per image. For example, for YOLOv3 real-time object recognition, InferX X1 processes 12.7 frames/second of 2-megapixel images at batch size = 1. Performance is roughly linear with image size, so frame rate approximately doubles for a 1-megapixel image. This is with a single DRAM.
InferX X1 will be available as chips for edge devices and on half-height, half-length PCIe cards for edge servers and gateways. It is programmed using the nnMAX Compiler, which takes Tensorflow Lite or ONNX models. The internal architecture of the inference engine is hidden from the user.
“The difficult challenge in neural network inference is minimizing data movement and energy consumption, which is something our interconnect technology can do amazingly well,” said Geoff Tate, CEO of Flex Logix, in a statement. “While processing a layer, the datapath is configured for the entire stage using our reconfigurable interconnect, enabling InferX to operate like a [custom chip], then reconfigure rapidly for the next layer. Because most of our bandwidth comes from local SRAM, InferX
requires just a single DRAM, simplifying die and package, and cutting cost and power.”
Added Tate, “Our on-chip Winograd conversion further reduces bandwidth due to weight loading because weights are 1.8x larger in Winograd format. Our mixed numerics capability enables customers to use integer 8 where practical but falls back to floating point as needed for achieving the desired prediction accuracy. This combination of features allows for high prediction accuracy, high throughput, low cost, and low power edge inference.”
nnMAX is in development now and will be available for integration in SoCs by Q3 2019. InferX X1 will finish its design the third quarter of 2019, and samples of chips and PCIe boards will be available shortly after.
Tate cofounded Flex Logix in 2014, and the company has raised more than $25 million to date.

