Watch all the Transform 2020 sessions on-demand here.
AI that creates original clips from text snippets isn’t as novel as it sounds. Last year, researchers detailed a system that tapped a pair of neural networks — layers of mathematical functions modeled after biological neurons — to generate videos 32 frames long and 64×64 pixels in size from descriptions like “playing golf on the grass.” But in a newly published paper on the preprint server Arxiv.org, scientists at Disney Research and Rutgers take the idea one step further with an end-to-end model that can create a rough storyboard and video depicting text from movie screenplays. Specifically, their text-to-animation model produces animations without the need for annotated data or a pretraining step, given input text describing certain activities.
“Automatically generating animation from natural language text finds application in a number of areas, [like] movie script writing, instructional videos, and public safety … [These systems] can be particularly valuable for screenwriting by enabling faster iteration, prototyping and proof of concept for content creators.” the researchers wrote. “In this paper, we develop a text-to-animation system which is capable of handling complex sentences … The purpose of the system is not to replace writers and artists, but to make their work more efficient and less tedious.”
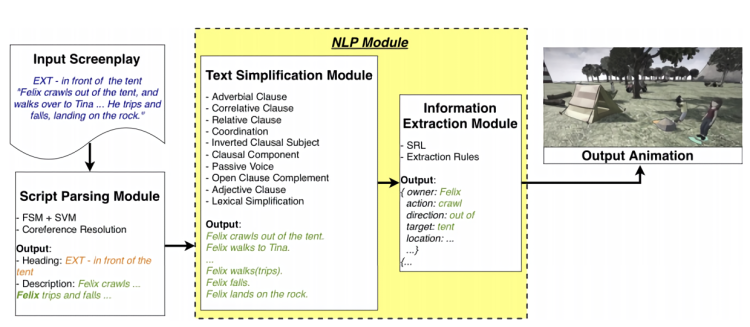
As the team explains, translating text into animation isn’t a straightforward task. Neither the input sentences nor the output animations have a fixed structure, which they say is the reason most text-to-video tools can’t handle complex sentences. To get around previous works’ limitations, then, the coauthors built a modular neural network comprising several components: a novel script-parsing module that automatically isolates relevant text from scene descriptions in screenplays; a natural language processing module that simplifies complex sentences using a set of linguistic rules and extracts information from the simplified sentences into predefined action representations; and an animation generation model that translates said representations into animation sequences.
Above: The text simplification stage in the proposed AI system.
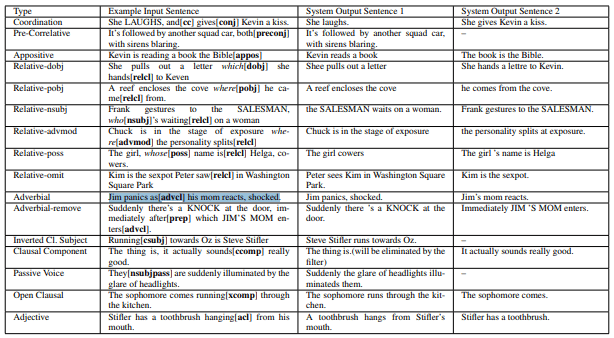
The simplification approach makes extracting key script info much easier, the researchers say, and toward that end, their system autonomously determines if a given snippet contains a particular syntactic structure and subsequently splits and assembles it into simpler sentences, recursively processing it until no further simplification is possible. A “coordination” step is next applied to sentences with the same syntactic relation with the head and serving the same functional role, and lastly, a lexical simplifier matches actions in the simplified sentences with 52 animations (expanded to 92 by a dictionary of synonyms) in a predefined library.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
Then, a pipeline dubbed Cardinal takes as input the actions and creates previsualizations in Unreal, a popular video game engine. Drawing on the predefined animations library, preuploaded objects, and models which it can use to create characters, it produces 3D animated videos that approximately depict the processed script.
To train the system, the researchers compiled a corpus of scene descriptions from 996 screenplays drawn from over 1,000 scripts scraped from freely available sources including IMSDb, SimplyScripts, and ScriptORama5. In the end, it comprised 525,708 descriptions containing 1,402,864 sentences, 920,817 (over 40%) of which had at least one action verb.
In a qualitative test that tasked 22 participants with evaluating 20 animations generated by the system on a five-point scale (e.g., if the video shown was a reasonable animation for the text, how much of the text information was depicted in the video, and how much of the information in the video was present in the text), 68% said that the system generated “reasonable” animation from input screenplays. “Besides the limitations of our system, [any] disagreement can be attributed to the ambiguity and subjectivity of the task,” the researchers added.
That said, the team conceded that the system isn’t perfect. Its list of actions and objects isn’t exhaustive, and occasionally, the lexical simplification fails to map verbs (like “watches”) to similar animations (“look”) or creates only a few simplified sentences for a verb that has many subjects in the original sentence. The researchers intend to address these shortcomings in future work.
“Intrinsic and extrinsic evaluations show reasonable performance of the system … [Eventually], we would like to leverage discourse information by considering the sequence of actions which are described in the text. This would also help to resolve ambiguity in text with regard to actions,” the team wrote. “Moreover, our system can be used for generating training data which could be used for training an end-to-end neural system.”

