
Watch all the Transform 2020 sessions on-demand here.
Some months back, OpenAI debuted an AI natural language model capable of generating coherent passages from millions of Wikipedia and Amazon product reviews, and more recently, it demonstrated an AI system — OpenAI Five — that defeated 99.4% of players in public Dota 2 matches. Building on those and other works, the San Francisco research organization today detailed Sparse Transformers, an open source machine learning system it claims can predict what comes next in text, image, and sound sequences 30 times longer than was previously possible.
“One existing challenge in AI research is modeling long-range, subtle interdependencies in complex data,” wrote OpenAI technical staff member Rewon Child and software engineer Scott Gray in a blog post. “Previously, models used on these data were specifically crafted for one domain or difficult to scale to sequences more than a few thousand elements long. In contrast, our model can model sequences with tens of thousands of elements using hundreds of layers, achieving state-of-the-art performance across multiple domains.”
A reformulation of Transformers — a novel type of neural architecture introduced in a 2017 paper (“Attention Is All You Need“) coauthored by scientists at Google Brain, Google’s AI research division — serves as the foundation of Sparse Transformers. As with all deep neural networks, Transformers contain neurons (mathematical functions loosely modeled after biological neurons) arranged in interconnected layers that transmit “signals” from input data and slowly adjust the synaptic strength — weights — of each connection. (That’s how the models extracts features and learns to make predictions.) Uniquely, though, Transformers have attention: Every output element is connected to every input element, and the weightings between them are calculated dynamically.
Above: Corpora memory usage before and after recomputation.
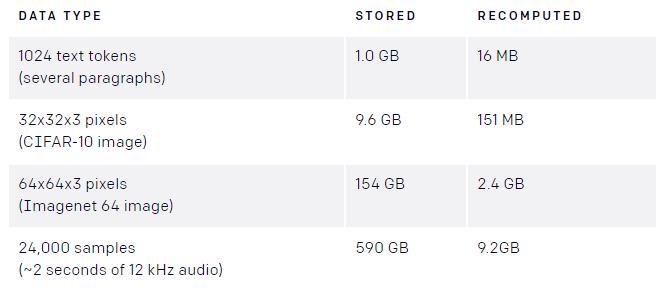
Attention normally requires creating an attention matrix for every layer and every so-called attention head, which isn’t particularly efficient from a computational standpoint. For instance, a corpus containing 24,000 samples of two-second audio clips or 64 low-resolution images might take up 590GB and 154GB of memory, respectively — far greater than the 12GB to 32GB found in the high-end graphics cards used to train AI systems.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
OpenAI’s approach minimizes memory usage by recomputing the matrix from checkpoints; the 590GB data set described above totals just 9.2GB after recomputation, and the 154GB compresses to 2.4GB. Effectively, the largest memory cost becomes independent of the number of layers within the model, allowing said model to be trained with “substantially greater” depth than previously possible.
Because a single attention matrix isn’t particularly practical for large inputs, the paper’s authors implemented sparse attention patterns where each output computed weightings only from a subset of inputs. And for neuron layers spanning larger subsets, they transformed the matrix through two-dimensional factorization — a step they say was necessary to preserve the layers’ ability to learn data patterns.

Above: Generating images with Sparse Transformers.
In experiments involving Sparse Transformers models trained on popular benchmark data sets including ImageNet 64, CIFAR-10, and Enwik8 and containing as many as 128 layers, the researchers say they achieved state-of-the-art density estimation scores and generated novel images. Perhaps more impressively, they even adapted it to generate five-second clips of classical music.
The researchers concede that their optimizations aren’t well-adapted to high-resolution images and video data. However, they pledge to investigate different patterns and combinations of sparsity in future work.
“We think … sparse patterns [are] a particularly promising avenue of research for the next generation of neural network architectures,” Child and Gray wrote.

