Watch all the Transform 2020 sessions on-demand here.
Photonic integrated circuits, or optical chips, promise a host of advantages over their electronic counterparts, including reduced power consumption and processing speedups. That’s why a cohort of researchers believe they might be tailor-made for AI workloads, and why some — including MIT Ph.D. candidate Yichen Shen — have founded companies to commercialize them. Shen’s startup — Boston-based Lightelligence, which has raised $10.7 million in venture capital funding to date — recently demonstrated a prototype that improves latency up to 10,000 times compared with traditional hardware and lowers power consumption by “orders of magnitude.”
Chipmaker Intel is another party investigating AI workloads on silicon photonics, and toward that end, scientists at the Santa Clara company recently detailed in a paper novel techniques that could bring optical neural networks a step closer to reality.
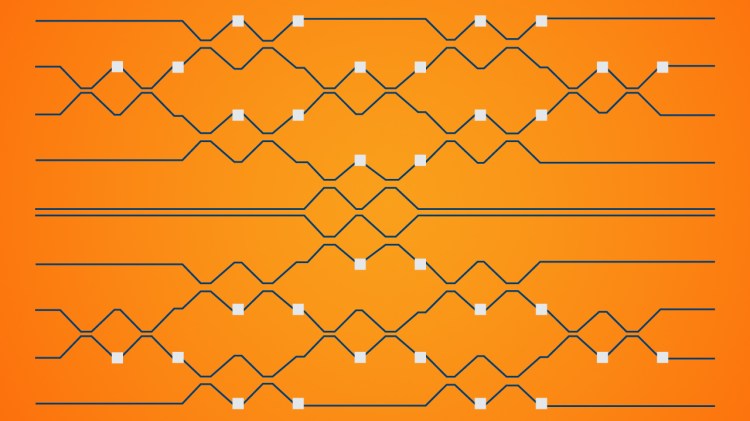
As the coauthors explain in a blog post published today, prior work has shown that a type of photonic circuit known as a Mach-Zender interferometer (MZI) can be configured to perform a two-by-two matrix multiplication between quantities related to the phases of two light beams. (In mathematics, a matrix is a rectangular array of numbers, symbols, or expressions arranged in rows and columns.) When these small matrix multiplications are arranged in a triangular mesh to create larger matrices, they produce a circuit that implements a matrix-vector multiplication, a core computation in deep learning.
The Intel team considered two architectures for building an AI system out of MZIs: GridNet and FFTNet. GridNet predictably arranges the MZIs in a grid, while FFTNet slots them into a butterfly-like pattern. After training the two in simulation on a benchmark deep learning task of handwritten digit recognition (MNIST), the researchers found that GridNet achieved higher accuracy than FFTNet (98% versus 95%) in the case of double-precision floating point accuracy, but that FFTNet was “significantly more robust.” In fact, GridNet’s performance fell below 50% with the addition of artificial noise, while FFTNet’s remained nearly constant.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
The scientists say their research lays the groundwork for AI software training techniques that might obviate the need to fine-tune optical chips post-manufacturing, saving valuable time and labor.
“As in any manufacturing process, there are imperfections, which means that there will be small variations within and across chips, and these will affect the accuracy of computations,” wrote Intel AI products group senior director Casimir Wierzynski. “If ONNs are to become a viable piece of the AI hardware ecosystem, they will need to scale up to larger circuits and industrial manufacturing techniques … Our results suggest that choosing the right architecture in advance can greatly increase the probability that the resulting circuits will achieve their desired performance even in the face of manufacturing variations.”

