
testsetset
The Transformer, a type of AI architecture introduced in a 2017 paper (“Attention Is All You Need“) coauthored by scientists at Google, excels at writing prose and product reviews, synthesizing voices, and crafting harmonies in the style of classical composers. But a team of Google researchers believed it could be taken a step further with AutoML, a technique in which a “controller” system identifies a “child” architecture that can then be tailored to a particular task. Remarkably, the result of their work — which they describe in a newly published paper and accompanying blog post — achieves both state-of-the-art translation results and improved performance on language modeling compared with the original Transformer.
They’ve released the new model — Evolved Transformer — as part of Tensor2Tensor, a library of open source AI models and data sets.
Traditionally, AutoML approaches begin with a pool of random models that the controller trains and evaluates for quality. The process is repeated thousands of times, and each time results in new vetted machine learning architectures from which the controller learns. Eventually, the controller begins to assign high probability to model components that achieve better accuracy on validation data sets and low probability to poorly scoring areas.
Discovering the Evolved Transformer with AutoML necessitated the development of two new techniques, the researchers say, because the task used to evaluate the performance of each architecture (WMT’14 English-German translation) was computationally expensive. The first — warm starting — seeded the initial model population with the Transformer architecture instead of random models, which helped ground the search. Meanwhile, the second — Progressive Dynamic Hurdles (PDH) — augmented the search to allocate more resources to the strongest candidates, enabling the controller to terminate the evaluation of “flagrantly bad” models early and award promising architectures more resources.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
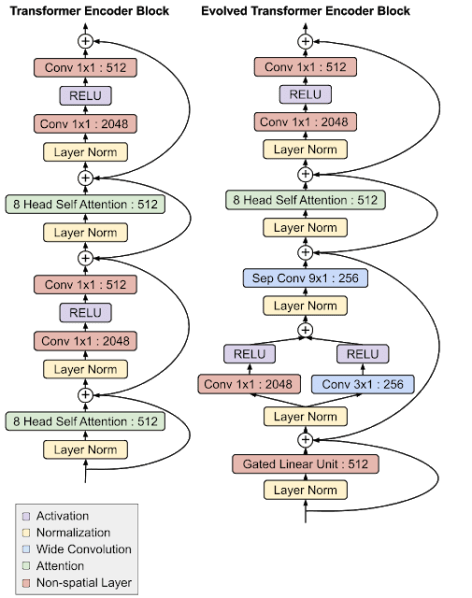
Above: The Evolved Transformer architecture.
So what’s so special about the Evolved Transformer? As with all deep neural networks, the Evolved Transformer contains neurons (functions) that transmit “signals” from input data and slowly adjust the synaptic strength — weights — of each connection, which is how the model extracts features and learns to make predictions. Furthermore, the Evolved Transformer has attention, such that every output element is connected to every input element and the weightings between them are calculated dynamically.
Like most sequence-to-sequence models, the Evolved Transformer contains an encoder that encodes input data (sentences in translation tasks) into embeddings (mathematical representations) and a decoder that uses those embeddings to construct outputs (translations).
But the team notes that it contains something rather unconventional, as well: convolutional layers at the bottom of both the encoder and decoder modules in branching pattern, such that inputs run through two separate convolutional layers before being added together. Whereas the original Transformer relied solely on attention, then, the Evolved Transformer is a hybrid that leverages the strengths of both self-attention and wide convolution.

Above: The Evolved Transformer’s performance compared with the Transformer.
In tests, the team compared the Evolved Transformer with the original Transformer on the English-German translation task used during the model search, and found that the former achieved better performance on both BLEU (an algorithm for evaluating the quality of machine-translated text) and perplexity (a measurement of how well probability distribution predicts a sample) at all sizes. At larger sizes, the Evolved Transformer reached state-of-the-art performance with a BLEU score of 29.8, and on experiments involving translation with different language pairs and language modeling, they observed a performance improvement of nearly two perplexity.

