
Watch all the Transform 2020 sessions on-demand here.
AI that can sketch images corresponding to descriptions is a thing that exists, thanks to the talented folks at Microsoft Research, the University of Albany, and JD AI Research. In a paper (“Object-driven Text-to-Image Synthesis via Adversarial Training“) scheduled to be presented at the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2019) conference in Long Beach, California, the team proposes a machine learning framework — ObjGAN — that can understand captions, sketch a layout, and refine the details based on the exact wording.
The paper’s coauthors claim their approach result in a “significant boost” in picture quality compared with previous state-of-the-art techniques. “[O]ur generators are able to utilize the fine-grained word- [and] object-level information to gradually refine the synthesized image,” they wrote. “Extensive experiments demonstrate the effectiveness and generalization ability of ObjGAN on text-to-image generation for complex scenes.”
A formidable challenge in developing text-to-image AI is imbuing the system with an understanding of object types, the team notes, as well as getting it to comprehend the relationships among multiple objects in a scene. Previous methods used image-caption pairs that provided only coarse-grained signals for individual objects, and even the best-performing models have trouble generating semantically meaningful photos containing more than one object.
To overcome these blockers, the researchers fed ObjGAN — which contains a generative adversarial network (GAN), a two-part neural network consisting of generators that produce samples and discriminators that attempt to distinguish between the generated samples and real-world samples — 100,000 labels (each with segmentation maps and five different captions) from the open source COCO data set. Over time, the AI system internalized the objects’ appearances and learned to synthesize their layouts from co-occurring patterns in the corpus, ultimately toward generating images conditioned on the pre-generated layouts.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.

Above: Images synthesized by ObjGAN.
In an attempt to achieve human-level performance in image generation, the team modeled in ObjGAN the way artists draw and refine complicated scenes. The system breaks input text into individual words and matches these words to specific objects in the image, and it leverages two discriminators — an object-wise discriminator and patch-wise discriminator — to determine whether the work is realistic and consistent with the sentence description.
The results aren’t perfect — ObjGAN occasionally spits out logically inconsistent samples, like a train marooned on a grassy knoll for the caption “A passenger train rolling down the tracks” — but they’re nonetheless impressive considering they’re synthesized from whole cloth.
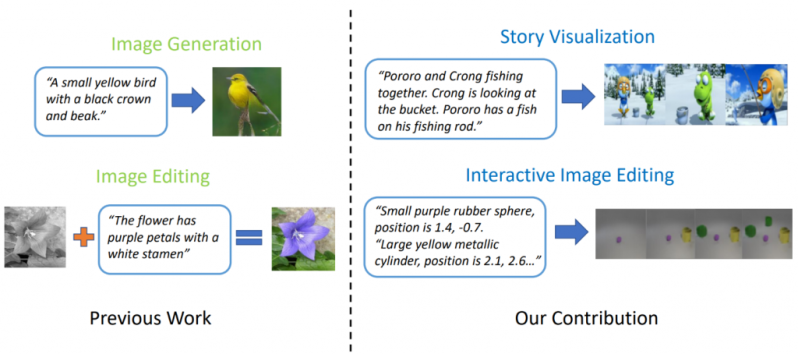
Above: Microsoft’s StoryGAN transforming descriptions into images.
Researchers at Microsoft, Microsoft Dynamics 365 Research, Duke University, Tencent AI Research, and Carnegie Mellon University took image generation a step further in a separate paper (“StoryGAN: A Sequential Conditional GAN for Story Visualization“) that describes a system — StoryGAN — capable of generating comic-like storyboards from multi-sentence paragraphs. StoryGAN is similarly built on a GAN, but uniquely contains a context encoder that dynamically tracks the story flow and two discriminators at the story and image levels to enhance the quality and the consistency of the generated sequences.
The team notes that StoryGAN can be extended for interactive image editing, where an input image can be edited sequentially based on the text instructions.

