testsetset
For millions of folks around the world, speech impairment is a fact of life. Roughly 7.5 million people in the U.S. have trouble vocalizing words and phrases, and disorders involving pitch, loudness, and quality affect about 5% of children by the first grade.
This poses a challenge for accessibility engineers developing AI-driven speech recognition and text-to-speech synthesis products, who have to accommodate a range of impairments for which limited data sets are available. Fortunately, scientists at Google are investigating ways to minimize word substitution, deletion, and insertion errors in speech models as a part of Parrotron, an ongoing research initiative that aims to help those with atypical speech become better understood.
“In today’s technological environment, limited access to speech interfaces, such as digital assistants that depend on directly understanding one’s speech, means being excluded from state-of-the-art tools and experiences,” wrote research scientist Fadi Biadsy and software engineer Ron Weiss in a blog post. “Parrotron makes it easier for users with atypical speech to talk to and be understood by other people and by speech interfaces, with its end-to-end speech conversion approach more likely to reproduce the user’s intended speech.”
Here’s an original speech sample:
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
And here’s Parrotron’s output:
Parrotron leverages an end-to-end AI system trained to convert speech from a person with an impediment directly into “fluent” synthesized speech, effectively skipping text generation. It considers only speech signals rather than visual cues such as lip movements, and it’s trained in two phases using parallel corpora of input/output speech pairs.
A general speech-to-speech conversion model is first fed samples from a large data set and then exposed to a corpus that adjusts its variables to atypical speech patterns from a target person. Normally, building a high-quality model of this sort would require a speaker to record hours of training data, but the researchers managed to extract data from an existing text-to-speech system, enabling them to make use of a preexisting transcribed speech recognition corpus.
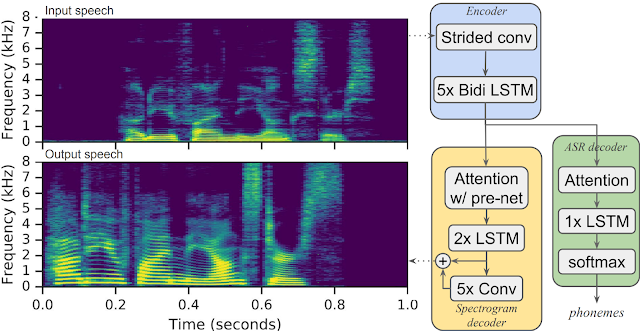
Above: An overview of Parrotron’s architecture.
The first phase drew on a data set of roughly 30,000 hours consisting of millions of utterance pairs, each including a natural utterance and a corresponding synthesized utterance from Google’s Parallel WaveNet text-to-speech system. The researchers note that the corpus includes snippets from “thousands” of speakers spanning hundreds of dialects, accents, and acoustic conditions, which made possible the modeling of a range of linguistic and non-linguistic contents, accents, and noise conditions with “typical” speech in the same language.
The fully trained conversion model seeds the second training phase, which involves a separate data set of utterance pairs optionally contributed by the target speaker but otherwise derived from sources like Google’s ongoing Project Euphonia. This second corpus is used to adapt the network to unique acoustic/phonetic, phonotactic, and language patterns, including things like how a speaker alters, substitutes, or removes certain vowels or consonants.
The team reports that training the system with a multitask objective — that is, having it predict target phonemes while simultaneously generating spectrograms (visual representations of frequencies of sound signals over time) of the target speech — led to significant quality improvements. They validated their approach with a group of speakers with ALS and with Dimitri Kanevsky, a deaf research scientist and mathematician at Google who recorded a personal corpus of 15 hours of speech. In Kanevsky’s case, Parrotron’s output reduced the word error rate of Google’s automatic speech recognition from 89% to 32%. As for the ALS speakers, human volunteers reported improvements in intelligibility in nearly all cases.
“Given the end-to-end speech-to-speech training objective function of Parrotron, even when errors are made, the generated output speech is likely to sound acoustically similar to the input speech, and thus the speaker’s original intention is less likely to be significantly altered and it is often still possible to understand what is intended,” wrote Biadsy and Weiss. “Furthermore, since Parrotron is not strongly biased to producing words from a predefined vocabulary set, input to the model may contain completely new invented words, foreign words/names, and even nonsense words.”
The team leaves to future work moving from a combination of independently tuned AI models to a single one, which they expect will result in “significant” performance improvements and greatly simplify Parrotron’s architecture. They’re currently recruiting volunteers to record sets of phrases — interested parties can sign up to contribute here.
Parrotron’s reveal comes after Google unveiled three separate accessibility efforts at its I/O 2019 developer conference: the aforementioned Project Euphonia, which aims to help people with speech impairments; Live Relay, which is designed to assist deaf users; and Project Diva, which gives people some independence and autonomy via Google Assistant. At the time, the Mountain View company pointed to a few metrics from the World Health Organization to back its efforts: Over 1 billion people, or 15% of the population, live with some sort of disability.

