
Watch all the Transform 2020 sessions on-demand here.
In an effort to bolster the development of cars capable of driving themselves around without human supervision, Lyft today released an autonomous vehicle data set that the company is calling the largest of its kind. It’s freely available in the existing nuScenes format, which was initially developed by Aptiv.
“Autonomous vehicles are expected to dramatically redefine the future of transportation. When fully realized, this technology promises to unlock a myriad of societal, environmental, and economic benefits,” said Lyft. “With this, we aim to empower the community, stimulate further development, and share our insights into future opportunities from the perspective of an advanced industrial autonomous vehicles program.”
In addition to over 55,000 human-labeled 3D annotated frames of traffic agents, the data set contains bitstreams from seven cameras and up to three lidar sensors, plus a drivable surface map and an underlying HD spatial semantic map that includes over 4,000 lane segments, 197 crosswalks, 60 stop signs, 54 parking zones, eight speed bumps, and 11 speed humps. Samples were collected from a fleet of Ford Fusion autonomous vehicles in a bounded geographic area, Lyft says. Each of them was equipped with a 40-beam roof lidar and 40-beam bumper lidars, wide-field-of-view cameras, and a long-focal-length camera mounted slightly pointing up to detect traffic lights.
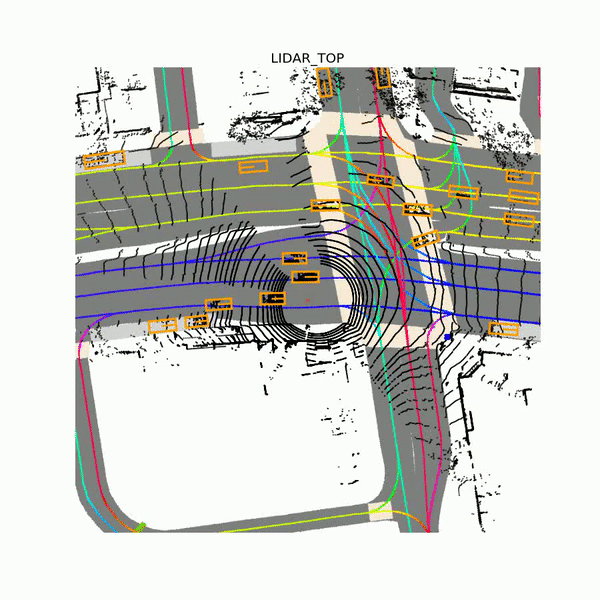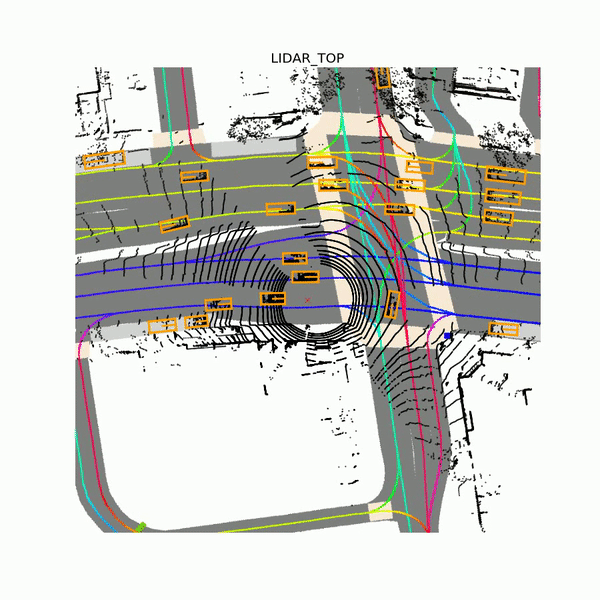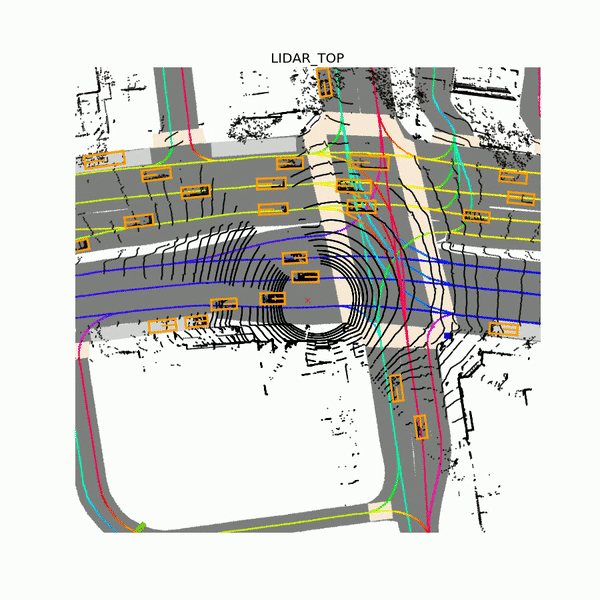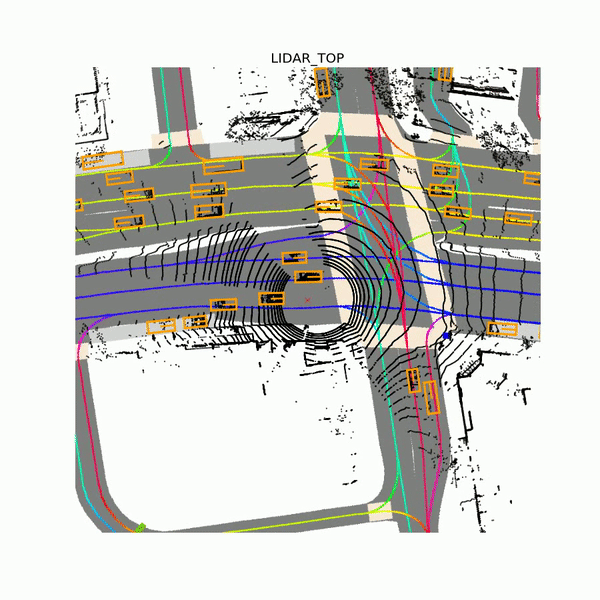
Above: Lidar data from Lyft’s Level 5 data set.
Coinciding with the data set’s release, Lyft announced an engineering challenge for developers interested in building machine learning models using the samples it contains. Lyft will offer $25,000 in cash prizes and fly out the top contestants to the NeurIPS conference in December.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
The corpus was compiled by Lyft’s Level 5 team, a group of over 300 engineers, applied researchers, product managers, operations managers, and more working toward building a self-driving system for ride-sharing. Since its founding in July 2017, the group has developed novel 3D segmentation frameworks, new methods of evaluating energy efficiency in vehicles, and techniques for tracking vehicle movement using crowdsourced maps.
In March 2018, Lyft began testing autonomous cars on public roads, a year after it completed tests on private roads and launched employee pilots. Separately, the company in May partnered with Google parent company Alphabet’s Waymo to enable the latter’s customers to hail driverless Waymo cars from the Lyft app in Phoenix, Arizona. And it has an ongoing collaboration with self-driving car startup Aptiv, which makes a small fleet of autonomous vehicles available to Lyft customers in Las Vegas.
The launch of Lyft’s data set comes after Waymo revealed a high-quality multimodal sensor data set for autonomous driving at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2019 in Long Beach, California in June. It features some 3,000 driving scenes totaling 16.7 hours of video data, 600,000 frames, and approximately 25 million 3D bounding boxes and 22 million 2D bounding boxes.
Other such open source collections include Mapillary’s Vistas data set of street-level imagery, the KITTI collection for mobile robotics and autonomous driving research, and the Cityscapes data set developed and maintained by Daimler, the Max Planck Institute for Informatics, and the TU Darmstadt Visual Inference Group.

