
testsetset
Google in March launched the Coral Dev Board, a compact PC featuring a tensor processing unit (Edge TPU) AI accelerator chip, and alongside it a USB dongle designed to speed up machine learning inference on existing Raspberry Pi and Linux systems (the Coral USB Accelerator). Since then, updates to the kits’ supporting resources have arrived at a steady clip, and today, Google released a new family of classification models — EfficientNet-EdgeTPU — it says are optimized to run on the Coral boards’ system-on-modules.
Both the training code and pretrained models for EfficientNet-EdgeTPU are available on GitHub.
“As reducing transistor size becomes more and more difficult, there is a renewed focus in the industry on developing domain-specific architectures — such as hardware accelerators — to continue advancing computational power,” wrote machine learning accelerator architect Suyog Gupta and Google Research software engineer Mingxing Tan. “Ironically, while there has been a steady proliferation of these architectures in data centers and on edge computing platforms, the [AI models] that run on them are rarely customized to take advantage of the underlying hardware.”
The goal of the EfficientNet-EdgeTPU project, then, was to tailor models derived from Google’s EfficientNets to the power-efficient, low-overhead Edge TPU chip. In previous tests, EfficientNets have demonstrated both higher accuracy and better efficiency over certain categories of existing AI system, reducing parameter size and FLOPS (floating point computations) by an order of magnitude.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
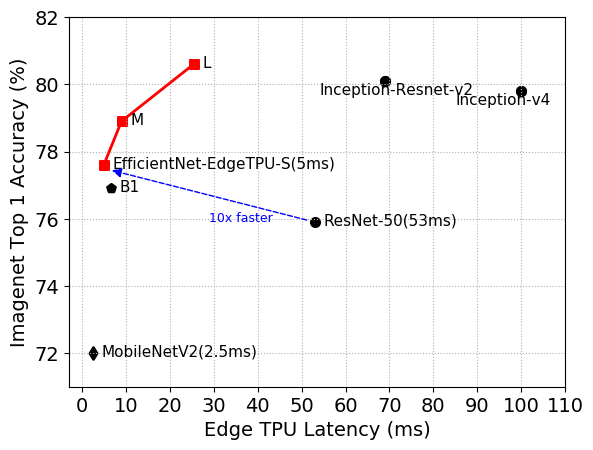
Above: The EfficientNet-EdgeTPU-S achieves higher accuracy, yet runs 10 times faster, than ResNet-50.
That’s because EfficientNets use a grid search to identify relationships among a baseline AI model’s scaling dimensions under a fixed resource constraint. The search determines the appropriate scaling coefficient for each dimension, and the coefficients are then applied to scale up the baseline model to the desired model size or computational budget.
According to Gupta, Tan, and colleagues, rearchitecting EfficientNets to leverage the Edge TPU required invoking the Google-developed AutoML MNAS framework. MNAS identifies ideal model architectures from a list of candidates by incorporating reinforcement learning to account for hardware constraints (in particular on-chip memory), and then by executing the various models and measuring their real-world performance before selecting the cream of the crop. The team complemented it with a latency predictor module that provided an estimate of algorithmic latency when executing on the Edge TPU.
The holistic approach produced a baseline model — EfficientNet-EdgeTPU-S — which the researchers scaled up by selecting the optimal combination of input image resolution scaling, network width, and depth scaling. In experiments, the resulting larger architectures — EfficientNet-EdgeTPU-M and EfficientNet-EdgeTPU-L — achieved higher accuracy at the cost of increased latency and ran faster on Edge TPUs compared with popular image classification models like Inception-resnet-v2 and Resnet50.
The release of EfficientNet-EdgeTPU comes a day after the debut of Google’s Model Optimization Toolkit for TensorFlow, a suite of tools that includes hybrid quantization, full integer quantization, and pruning. Of note is post-training float16 quantization, which reduces AI model sizes up to 50% while sacrificing very little accuracy.

