
testsetset
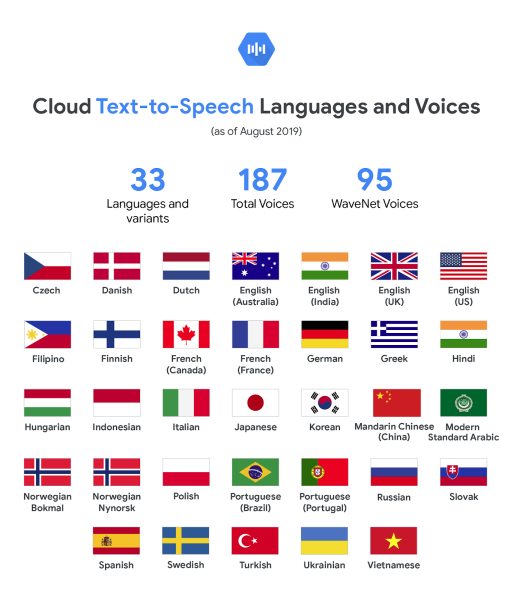
Back in February, Google announced a series of updates to its Google Cloud Platform (GCP) AI text-to-speech and speech-to-text services that introduced multichannel recognition, device profiles, and additional languages synthesized by an AI system — WaveNet — pioneered by Google parent company Alphabet’s DeepMind. Building on those enhancements, the Mountain View company today expanded the number of new variants and voices in Cloud Text-to-Speech by nearly 70%, boosting the total number of languages and variants covered to 33.
Now, thanks to the addition of 76 new voices and 38 new WaveNet-powered voices, Cloud Text-to-Speech boasts 187 total voices (up from 106 at the beginning of this year) and 95 total WaveNet voices (up from 57 in February and 6 a year and a half ago). Among the newly supported languages and variants are Czech, English (India), Filipino, Finnish, Greek, Hindi, Hungarian, Indonesian, Mandarin Chinese (China), Modern Standard Arabic, Norwegian (Nynorsk), and Vietnamese, all of which have at least one AI-generated voice.
“With these updates, Cloud Text-to-Speech developers can now reach millions more people across numerous countries with their applications — with many more languages to come,” wrote product manager Dan Aharon. “This enables a broad range of use cases, including call center IVR, interacting with IoT devices in cars and the home, and audio-enablement of books and other text-based content.”
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
For the uninitiated, WaveNet mimics things like stress and intonation, referred to in linguistics as prosody, by identifying tonal patterns in speech. It produces much more convincing voice snippets than previous speech generation models — Google says it has already closed the quality gap with human speech by 70% based on mean opinion score — and it’s also more efficient. Running on Google’s tensor processing units (TPUs), custom chips packed with circuits optimized for AI model training, a one-second voice sample takes just 50 milliseconds to create.
Aharon notes that Cloud Text-to-Speech handily leapfrogs rivals like Microsoft’s Azure Speech Services and Amazon Poly by the number of AI voices on offer: 11 of Polly’s 58 voices are generated by an AI model, while only 5 of Azure Speech Services’ voices are AI-synthesized. Moreover, Polly and Azure Speech Services feature only 2 and 4 total languages/variants with AI-powered voices, respectively.
“When customers call into contact centers, use verbal commands with connected devices in cars or in their homes, or listen to audio conversions of text-based media, they increasingly expect a voice that sounds natural and human,” wrote Aharon. “Businesses that offer human-sounding voices offer the best experiences for their customers, and if that experience can also be provided in numerous languages and countries, that advantage becomes global.”
Cloud Text-to-Speech is free to use up to the first million characters processed by the API.
