
testsetset
If you’re a Google Cloud Platform (GCP) customer who’s currently tapping the suite’s artificially intelligent (AI) text-to-speech or speech-to-text services, good news: New features are heading your way. As of today, the Cloud Text-to-Speech API can recognize additional languages — seven languages and dialects, to be exact — and speak with new voices, including 31 synthesized by WaveNet, a machine learning network developed by Google parent company Alphabet’s DeepMind.
Not to be outdone, the Cloud Speech-to-Text API’s multichannel recognition feature, which helps distinguish between multiple audio channels, is launching in general availability after a months-long preview. So too are improved speech recognition models that are over 60 percent more accurate than their progenitors, and Device Profiles, a feature that tweaks GCP voices for optimal playback on a range of hardware.
“The ability to recognize and synthesize speech is critical for making human-machine interaction natural, easy, and commonplace, but it’s still too rare,” Google product manager Dan Aharon wrote in a blog post. “When creating intelligent voice applications, speech recognition accuracy is critical.”
Cloud Speech-to-Text
Google, you might recall, in April 2018 launched new premium speech-to-text models tailored to specific use cases: enhanced phone call and video. (Video was available at a premium price, while access to the new phone model was tied to participation in Google’s crowdsourced data-sharing program.) The video model is optimized for long recordings (over two hours) with lots of background noise and conversations involving four or more speakers (like TV broadcasts of sporting events), while the phone model works best with two to four people and minimal noise (think static from phone lines and hold music).
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
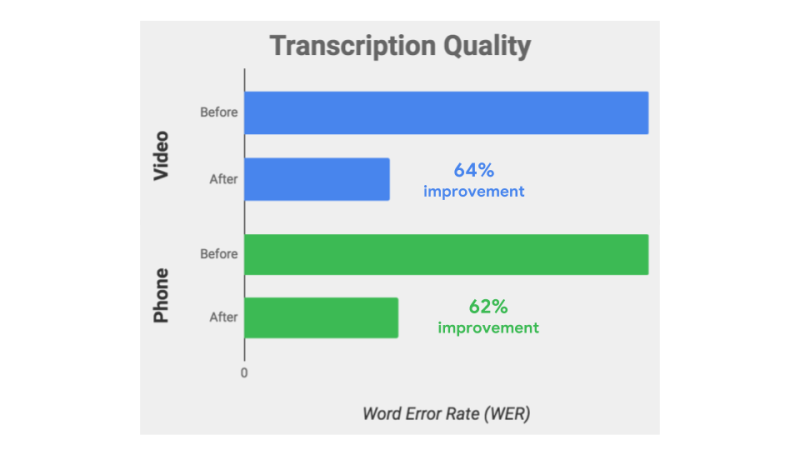
At the time, Google said the video model, which uses learning technology similar to that employed by YouTube captioning, showed a 64 percent reduction in errors compared to the default model on a video test set. Google today claims that the enhanced phone model, which is now broadly available for enterprise Google Cloud customers, has 62 percent fewer transcription errors, improved from 54 percent last year.
The aforementioned multi-channel recognition feature, which offers an easier way to transcribe multiple channels of audio by automatically denoting the separate channels for each word, is also generally available and now qualifies for SLA and “other enterprise-level guarantees.” For audio samples that aren’t recorded separately, Cloud Speech-to-Text offers diarization, which uses machine learning to tag each word with an identifying speaker number. (The accuracy of the tags improves over time, Google said.)
Cloud Text-to-Speech
In August 2018, Google introduced 17 voices generated with WaveNet across 14 languages and variants, for a total of 26 WaveNet voices. This week, the company is rolling out 31 new WaveNet voices and 24 new standard voices, bringing the total number of WaveNet voices to 57 and the total number of voices Cloud Text-to-Speech supports to 106. (Microsoft’s Azure Speech Service API, by comparison, offers three AI-generated voices in preview and 75 standard voices.)
For the uninitiated, WaveNet mimics things like stress and intonation in speech — sounds referred to in linguistics as prosody — by identifying tonal patterns. It produces much more convincing voice snippets than previous speech generation models — Google says it has already closed the quality gap with human speech by 70 percent based on mean opinion score — and it’s also more efficient. Running on Google’s tensor processing units (TPUs), custom chips packed with circuits optimized for AI model training, a one-second voice sample takes just 50 milliseconds to create.
Google says that with the seven new languages now offered through Text-to-Speech — Danish, Portuguese, Russian, Polish, Slovakian, Ukrainian, and Norwegian Bokmål — Cloud Text-to-Speech now supports 21 languages in all.
Device Profiles
Device Profiles, which were previously available in beta, are also launching broadly today. In a nutshell, they let customers optimize the voices produced by Cloud Text-to-Speech for playback on different types of hardware. These customers can create a device profile for wearables with smaller speakers, for example, or several specially tuned for car speakers and headphones, which is particularly handy for devices that don’t support specific frequencies. Cloud Text-to-Speech can automatically shift out-of-range audio to within hearing range, enhancing clarity.
“The physical properties of each device, as well as the environment they are placed in, influence the range of frequencies and level of detail they produce (e.g., bass, treble, and volume),” the Google Cloud team wrote in a blog post last year. “The … audio sample [resulting from Audio Profiles] might actually sound worse than the original sample on laptop speakers, but will sound better on a phone line.”
Eight Device Profiles are supported at launch:
- Wearables (e.g., Wear OS devices)
- Handsets
- Headphones
- Small Bluetooth speakers (Google Home mini)
- Medium Bluetooth speakers (Google Home)
- Home entertainment systems (Google Home Max)
- Car speakers
- Interactive voice response (IVR) systems
Price reduction
Lastly, Google’s reducing the price of Cloud Speech-to-Text.
It’s cutting the rates for the enhanced video and phone models to $0.009 per 15 seconds of audio for enterprise users who don’t opt into the aforementioned data-sharing program and reducing standard model costs to $0.006 per 15 seconds. Customers who do opt to share their data logs with Google will pay $0.004 per 15 seconds for access to the standard model, and $0.006 per 15 seconds for the enhanced models.
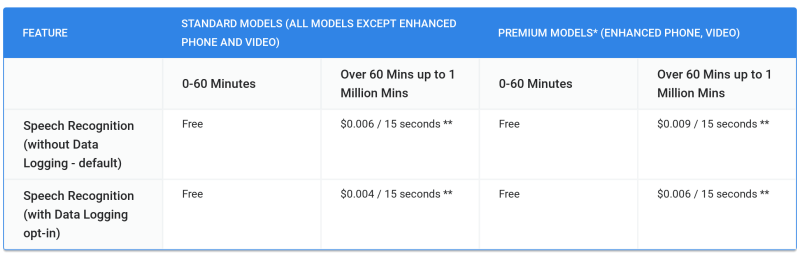
Above: New pricing for Cloud Speech-to-Text.
As before, models are free for the first 60 minutes every month.
Today’s slew of updates comes after the debut of transcript generation, text detection, and object tracking in Google’s Cloud Video Intelligence API, and after the launch of Kubeflow Pipelines, a machine learning workflow meant to make ML easier for developers and data scientists. The Mountain View company also recently launched Google AI Hub — a one-stop shop for things like popular datasets on Kaggle and TensorFlow embeddings — in alpha.

