Watch all the Transform 2020 sessions on-demand here.
In 2017, Geoffrey Hinton — a foremost theorist of AI and a recent recipient of the Turing Award — proposed with students Sara Sabour and Nicholas Frosst a machine learning architecture called CapsNet, a discriminately trained and multilayer approach that achieved state-of-the-art image classification performance on a popular benchmark. In something of a follow-up to their initial work, Hinton, Sabour, and researchers from the Oxford Robotics Institute this week detailed a version of the capsule network that bests leading algorithms in an unsupervised classification task.
Their work is described in a paper (“Stacked Capsule Autoencoders“) published on the preprint server Arxiv.org.
For the uninitiated, capsule systems make sense of objects by interpreting organized sets of their interrelated parts geometrically. Sets of mathematical functions (capsules) that individually activate for various object properties (like position, size, and hue) are tacked onto a convolutional neural network (a type of AI model often used to analyze visual imagery), and several of their outputs are reused to form more “stable” representations for higher-order capsules. Since these representations remain intact throughout, capsule systems can leverage them to identify objects even with changes in viewpoint, such as when the positions of parts are swapped or transformed.
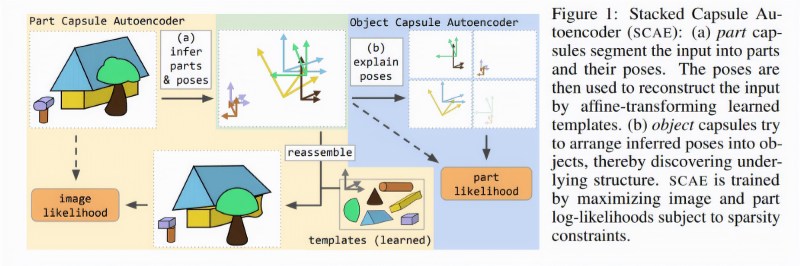
Above: A diagram illustrating the proposed capsule system.
Another unique thing about capsule systems? They route with attention. As with all deep neural networks, capsules’ functions are arranged in interconnected layers that transmit “signals” from input data and slowly adjust the synaptic strength — weights — of each connection. (That’s how they extract features and learns to make predictions.) But where capsules are concerned, the weightings are calculated dynamically according to previous-layer functions’ ability to predict the next layer’s outputs.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
Hinton and colleagues’ recent work investigates a neural encoder that looks at image samples and attempts to suss out the presence and poses of objects. It’s trained with a decoder that predicts the pose of already discovered parts of images (segmented by an autoencoder) using a mixture of pose predictions, and that models each image pixel as a mixture of predictions made by transformed parts. The capsule system is then learned on unlabeled data, and the vectors (mathematical representations) of presences are clustered together to capture spatial relationships among whole objects and parts.
The coauthors noticed that the vectors of presence probabilities for object capsules are more likely to form tight clusters, and that assigning a class to each tight cluster produces state-of-the-art results in unsupervised classification on the Street View House Numbers Dataset (a data set of over 600,000 real-world images of house numbers from Google Street View Images). Furthermore, this realization led to near-state-of-the-art results on MNIST, a corpus of handwritten digits, and further improved performance with fewer than 300 parameters.

