
Watch all the Transform 2020 sessions on-demand here.
Though it’s a well-established fact that mammographies (mammograms) reduce breast cancer mortality rates, the high proportion of false-positive recalls associated with such screenings has accelerated development of AI-driven systems from IBM, MIT’s Computer Science and Artificial Intelligence Laboratory, and others. But these aren’t perfect, either, because most models operate on a single screening exam.
This shortcoming motivated a team of researchers at New York University’s Center for Data Science and Department of Radiology to propose a machine learning framework that takes advantage of prior exams in making a diagnosis (“Screening Mammogram Classification with Prior Exams “). They say that in preliminary tests, it reduced the error rate of the baseline and achieved an area under the curve (a metric indicating performance at all classification thresholds) of 0.8664 for predicting malignancy in a screening population.
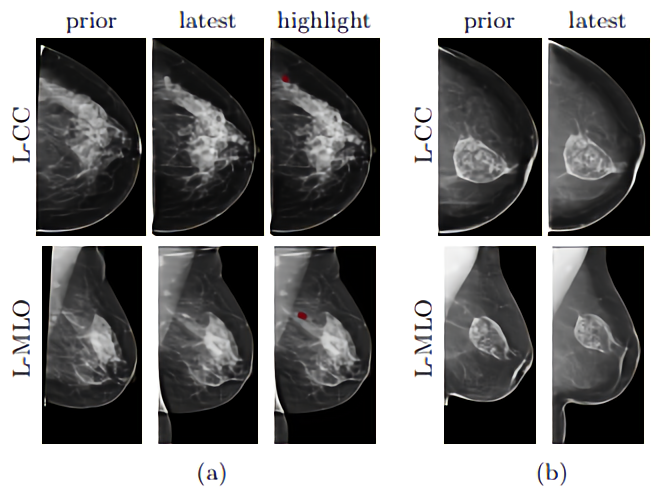
“Radiologists often compare current mammograms to prior ones to make more informed diagnoses,” wrote the coauthors. “For instance, if a suspicious region grows in size or density over time, radiologists can be more confident that it is malignant. Conversely, if a suspicious region does not grow, then it is probably benign.”
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
The team trained an ensemble of machine learning models on the open source New York University Breast Cancer Screening Dataset, with each screening containing at least one image corresponding to the four views typically used in mammography screenings (right craniocaudal, left craniocaudal, right mediolateral oblique, and left mediolateral oblique). They used four binary labels to indicate the presence or absence of benign or malignant findings in the left or the right breast, taking care to consider only the subset of the data set that included patients for which prior exams are available.
The assembled corpus contained 127,451 exam pairs from 43,013 patients, where 2,519 pairs had at least one biopsy performed.
The team trained an ensemble of machine learning models on the data and then compared their performance using only a portion of the training data set. They note that there wasn’t an observable improvement over the baseline for benign predictions, which they attributed to the algorithms’ tendency to focus on regions of scans with significant changes. (Not many changes accompany benign findings.) But they found that one of the models — AlignLocalCompare — showed substantial improvement with respect to the malignant findings, predicting the likelihood of a tumor with 0.97 probability, compared with the baseline’s prediction of 0.73 with about a year gap between two exams for both patients.

