
Watch all the Transform 2020 sessions on-demand here.
Databricks is launching open source project Delta Lake, which Databricks CEO and cofounder Ali Ghodsi calls the company’s biggest innovation to date, bigger even than its creation of the Apache Spark machine learning library. Delta Lake is a storage layer that sits on top of data lakes to ensure reliable data sources for machine learning and other data science-driven pursuits.
The announcement was made today at the Spark+ AI Summit in San Francisco and follows Databricks’ $250 million funding round in February, bringing the company’s valuation to $2.75 billion.
Data lakes, which offer a way to pool data and break down data silos, have grown in popularity with the rise of big data and machine learning.
Databricks’ cofounders created the Apache Spark machine learning library while they were students at the University of California, Berkeley. The Apache Software Foundation took over control of the project in 2013. Delta Lake is compatible with Apache Spark and MLflow, Databricks’ other open source project, which debuted last year.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
“Delta Lake looks at all the data that’s coming in and makes sure that this data adheres to the schema that you’ve specified. That way, any data that makes it into the Delta Lake will be correct and reliable,” Ghodsi said. “It adds full-blown ACID transaction to any operation you do on your Delta Lake, so operations on Delta Lake are always correct [and] you can never run into … partial errors or leftover data.”
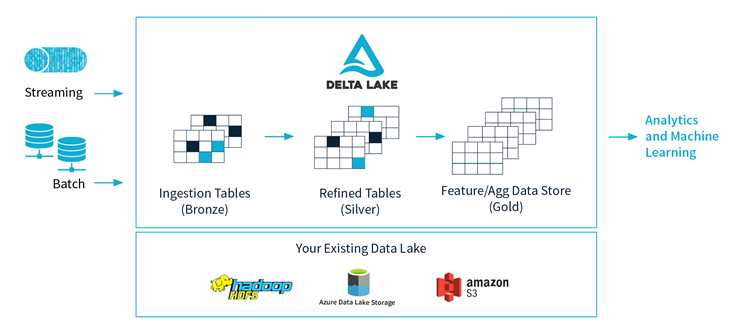
Delta Lake can operate in the cloud, in on-premise servers, or on devices like laptops. It can handle both batch and streaming sources of data.
“It lets you now mix batch and streaming data in ways that have been impossible in the past. In particular, you can have one table that you have streaming updates coming into, and you can have multiple concurrent readers that are reading it in streaming or batch. And all of this will just work because of the transaction, without any concurrency issues or corruption,” Ghodsi said.
A time travel feature will also allow users to access earlier versions of their data for audits or to reproduce MLflow machine learning experiments. The tool can handle Parquet files used to store large data sets.
A proprietary version of Delta Lake was made available to some Databricks customers a year ago and is now used by more than 1,000 organizations. Early adopters of Delta Lake include Viacom, McGraw-Hill, and Riot Games.
In other open-source news for Databricks today, Microsoft’s Azure Machine Learning joined the MLflow project.

