
Watch all the Transform 2020 sessions on-demand here.
Cloud file syncing and sharing service Dropbox today disclosed more of the technical details underpinning the optical character recognition (OCR) feature that’s now available in the company’s flagship Android and iOS apps for people who work in organizations that pay for the Dropbox Business service tier.
The feature kicks into action after you scan a document using the camera on your mobile device. The app then lets you crop or rotate the document as necessary before saving it as a PDF in Dropbox. In August the company said it was using computer vision to detect the edges of documents that the app scans, but all this time the system for doing OCR has been a mystery. Today that changed.
OCR, of course, has been around for a while. And the idea of doing OCR with the help of deep learning — a type of artificial intelligence (AI) that entails training artificial neural networks on data and then getting the neural networks to make inferences about new data — is not in itself new. Open source software to do it is available for the taking on GitHub. Google has looked to deep learning to more effectively do OCR on numbers in Google Street View imagery, for one thing.
Dropbox hasn’t talked much about AI over the years, even though it has lots of users and lots of data. So today’s lengthy blog post from senior software engineer Brad Neuberg is noteworthy.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
The initial version of the OCR system drew on a commercially available software development kit (SDK). Dropbox opted to roll its own in order to save money and also increase accuracy, because the commercially available system was primarily built for actual hardware scanners, not scanners that use cameras on mobile devices.
To train its system, Dropbox looked to its user base.
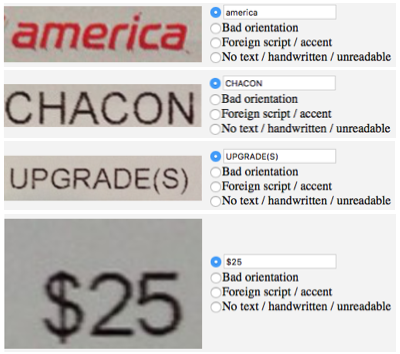
“We began by collecting a representative set of donated document images that match what users might upload, such as receipts, invoices, letters, etc.,” Neuberg wrote. “To gather this set, we asked a small percentage of users whether they would donate some of their image files for us to improve our algorithms. At Dropbox, we take user privacy very seriously and thus made it clear that this was completely optional, and if donated, the files would be kept private and secure. We use a wide variety of safety precautions with such user-donated data, including never keeping donated data on local machines in permanent storage, maintaining extensive auditing, requiring strong authentication to access any of it, and more.”
Rather than rely exclusively a third-party service for the menial work of labeling data like Amazon’s longstanding Mechanical Turk service, Dropbox — you guessed it! — built its own system, named DropTurk, which actually can at times make use of Mechanical Turk.
“DropTurk can submit labeling jobs either to MTurk [Mechanical Turk] (if we are dealing with public non-user data) or a small pool of hired contractors for user-donated data,” Neuberg wrote. “These contractors are under a strict non-disclosure agreement (NDA) to ensure that they cannot keep or share any of the data they label. DropTurk contains a standard list of annotation task UI templates that we can rapidly assemble and customize for new data sets and labeling tasks, which enables us to annotate our data sets quite fast.”
Above: What Dropbox’s DropTurk service looks like.
To predict the text equivalent of a cut-up image of a specific word within a document, Dropbox sends the image through a convolutional neural network, then a bi-directional long short-term memory (LSTM) network, and finally a connectionist temporal classification (CTC) system, Neuberg wrote. All of these technologies have been around for many years but have seen a resurgence in the past six years or so. The system relies partly on the Google-led TensorFlow open source deep learning framework.
To strengthen this system, Dropbox drew on fake data — little bits from Project Gutenberg books that then got transformed in simple ways.
Despite Dropbox’s journey off of the Amazon Web Services (AWS) public cloud and onto its own data center infrastructure, Dropbox went ahead and trained its model using the G2 virtual machine (VM) instances accelerated with graphics processing units (GPUs) and stored some data in the AWS S3 storage service.
To further improve the model, Dropbox then tapped its small collection of actual images of words, instead of synthetic ones. Then it made the jump from predicting individual words to handling entire documents, each of which can contain many words. It called on the Maximally Stable Extremal Regions in the open source computer vision software library OpenCV.
The team tinkered with the system some more and trained the model on more synthetic words. And then it decided to have the model perform the inferences on standard x86 chips in its own data centers, as opposed to GPUs. Finally it began turning on the feature for a small group of users. Dropbox tested the performance of its in-house OCR technology and found that its own was just as good as, if not better than, the commercially available system.
See Neuberg’s full blog post for more detail.

