
Watch all the Transform 2020 sessions on-demand here.
Facebook AI Research (FAIR), Facebook’s AI and machine learning division, today detailed work on a comprehensive AI chatbot framework called Blender. FAIR claims that Blender, which is available in open source on GitHub, is the largest-ever open-domain chatbot and outperforms existing approaches to generating dialogue while “feel[ing] more human,” according to human evaluators.
FAIR says Blender is the culmination of years of research to combine empathy, knowledge, and personality into one system. To this end, the underlying models — which benefit from improved decoding and skill blending techniques — contain up to 9.4 billion parameters (configuration variables that define skill on a given problem), or 3.6 times more than previous systems.
Blender promises to make interactions with conversational AI systems like Alexa, Siri, and Cortana more natural than before, whether in enterprise, industrial, or consumer-facing contexts. That’s because they’re able to ask and answer a wide range of questions; display knowledge about specific topics; and express sentiments like empathy, seriousness, or playfulness as circumstances dictate.
Blending skills and generation strategies
To achieve Blender’s state-of-the-art performance, researchers at FAIR focused on two engineering steps: blending skills and generation strategy.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
“Blending skills” refers to selecting tasks that outperform larger models that lack tuning. As the FAIR researchers point out in a paper, chatbot improvements can be attained by fine-tuning models on data that emphasizes desirable conversational skills. As it turns out, tuning can also minimize undesirable traits learned from large data sets, such as toxicity.
With respect to generation strategy, the choice of decoding algorithm — the algorithm used to generate text from a language model — has an outsized impact on a chatbot’s responses. Because the length of a bot’s responses tend to correspond to human judgments of quality, decoders that strike an appropriate balance are desirable. Responses that are too short are typically perceived as dull or showing a lack of interest, while those that are too long imply waffling or distraction.
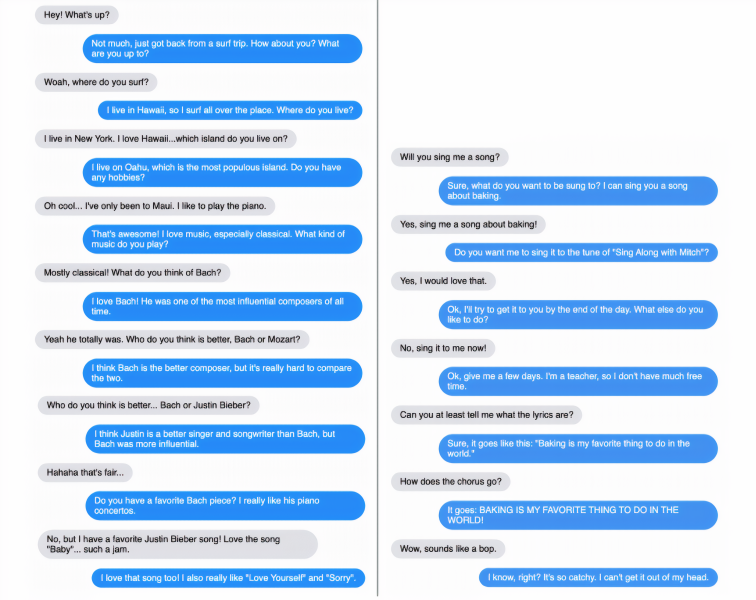
Above: A conversation with a Blender chatbot. Blender’s responses are in blue.
Over the course of these engineering steps, the researchers tested three types of model architectures, all of which used Transformers as a base. Transformers — a Google innovation — contain neurons (mathematical functions) arranged in layers that transmit signals from input data and adjust the strength (weights) of each connection, as with all deep neural networks. That’s how they extract features and learn to make predictions, but Transformers also have attention. This means every output element is connected to every input element and the weightings between them are calculated dynamically.
First up was a retriever model that, given a dialogue history (or context) as input, selected the next dialogue response by scoring a large set of candidate responses and outputting the highest-scoring one. The FAIR researchers employed a poly-encoder architecture that encoded features of the context using representations attended to by each candidate response, which they say resulted in improved performance while remaining “tractable” to compute, compared with other architectures, like cross-encoders.
The second model was a generator that produced responses rather than retrieving them from a fixed set. Three models were considered by size, ranging from 90 million parameters to 2.7 billion parameters to 9.4 billion parameters.
The third model attempted to address issues with the generator, namely its tendency to synthesize repetitive responses and to “hallucinate” knowledge. It took a “retrieve and refine” (RetNRef) approach, where the above-described retrieval model produced a response when provided a dialogue history, which was then appended to the input sequence of the generator. In this way, the generator learned when to copy elements of responses from the retriever and when not to so it could output more interesting, engaging, and “vibrant” responses. (Retriever models produce human-written responses that tend to include more vibrant language than standard generative models.)
The FAIR team paired a Wizard Generative model with another retriever that together determined when to incorporate knowledge into chatbot responses. The two models produce a set of initial knowledge candidates and then rank those candidates, after which they select a single sentence and use it to condition response generation. A classifier chooses whether to perform retrieval or not on a per-dialogue basis so as to avoid serving knowledge when it’s not required.
Decoding
For the generative models, the FAIR researchers used a beam search decoder method to generate responses to given dialogue contexts. Beam search maintains a set of partially decoded sequences, called hypotheses, that are appended to form sequences and then scored so the best sequences bubble to the top.
To control the length of the chatbot’s responses, the FAIR team considered two approaches: a hard constraint on the minimum generation length and a classifier that predicted the length of responses and set the minimum generation length constraint to its corresponding prediction. The latter was more complex but resulted in variable-length responses to questions, ensuring the chatbot served long responses when they seemed appropriate.
Training the models
To prep the various models that make up Blender, the researchers first performed pretraining, a step that conditions machine learning models for particular tasks. They used Facebook’s own Fairseq, a toolkit that supports the training of custom language models, with data samples from a Reddit corpus containing 1.5 billion comments (with two sets of 360,000 comments each reserved for validation and testing) pruned for known bots, non-English subreddits, deleted comments, comments with a URL, and comments of a certain length.
Next, the FAIR team fine-tuned the models using another Facebook-developed suite — ParlAI — designed for training and testing dialogue models. One training corpus selected was ConvAI2, which contains 140,000 utterances involving paired volunteers getting to know each other by asking and answering friendly questions. Another was Empathetic Dialogues, which consists of 50,000 crowdsourced utterances grounded in an emotional situation. Yet another data set — the Wizard of Wikipedia — comprises 194,000 utterances of 1,250 topics, where each conversation begins with a randomly chosen topic and the goal is to display expert knowledge.
A fourth fine-tuning data set — Blended Skill Talk — aimed to blend the previous three sets (ConvAI2, Empathetic Dialogues, and Wizard of Wikipedia) to combine their respective skills during dialogue. Here, 76,000 utterances were collected with a guided and unguided human speaker, where the guided speaker could select utterances suggested by bots trained on the three individual data sets.
Evaluations
Post-training, the researchers evaluated Blender’s performance by comparing it with Google’s latest Meena chatbot, a machine learning model with 2.6 billion parameters. Human volunteers were tasked with answering two questions — “Who would you prefer to talk to for a long conversation?” and “Which speaker sounds more human?” — given 100 publicly released and randomized logs from Meena and the same number of logs generated by Blender. In each case, the volunteers were shown series of dialogues between humans paired with the respective chatbots.
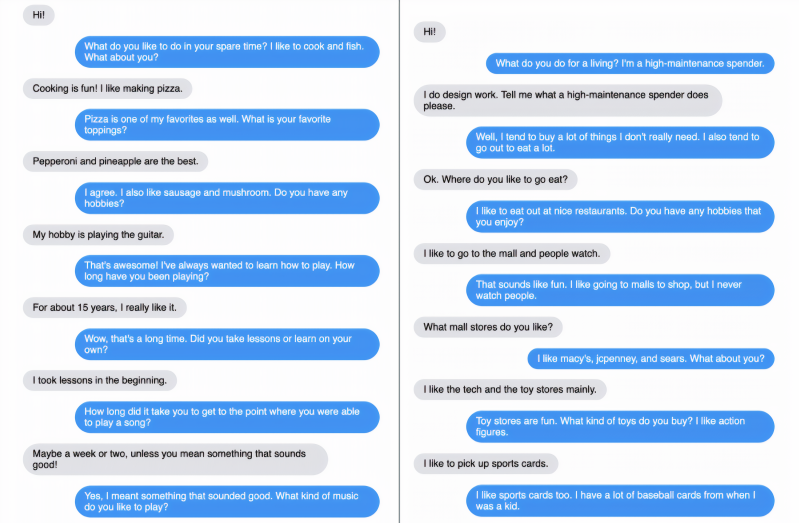
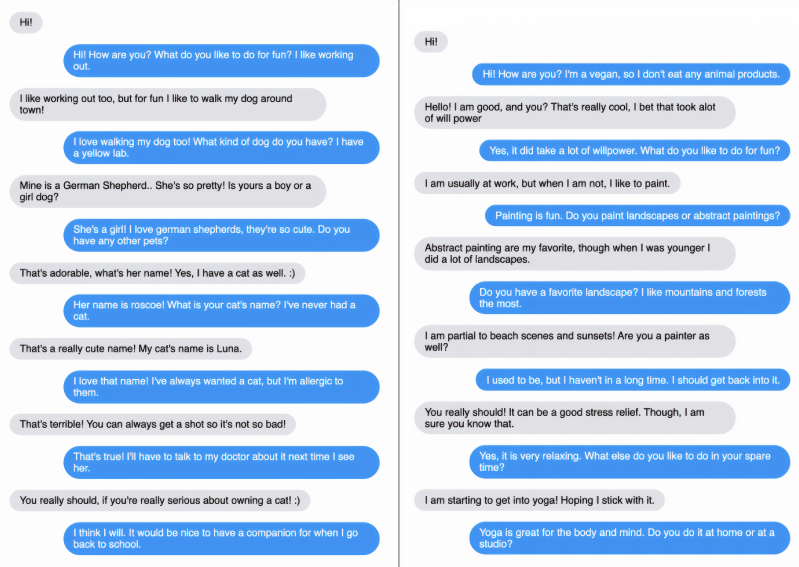
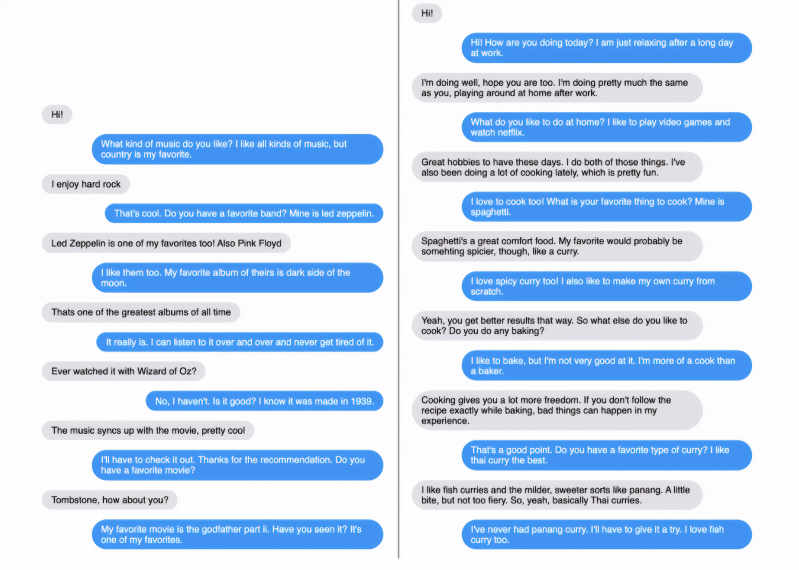
The topics of conversation ranged from cooking, music, movies, and pets to yoga, veganism, instruments, and malls — with the Blender models often going into detail when asked and naming relevant stores, bands, movies, actors, pet species, and pet names. In one example, Blender offered a nuanced answer to a question about how Bach compared with Justin Beiber, while a request that Blender write a song indeed yielded lyrics — although nothing particularly poetic.
When presented with chats showing Meena in action and chats showing Blender in action, 67% of the evaluators said the best-performing Blender-powered chatbot — the one with a generative model containing 9.4 billion parameters pretrained on the Blended Skill Talk corpus — sounded more human. About 75% said they’d rather have a long conversation with the 2.7 billion-parameter fine-tuned model than with Meena. And in an A/B comparison between human-to-human and human-to-Blender conversations, the volunteers expressed a preference for models fine-tuned on Blended Skill Talk 49% of the time, while models trained only on public domain conversations were preferred just 36% of the time.
Problematically, further experiments showed that Blender sometimes produced responses in the style of offensive samples from the training corpora — mostly from Reddit comments. The FAIR researchers say that fine-tuning on the Blended Skill Talk data set mitigated this to an extent but addressing it comprehensively would require using an unsafe word filter and a kind of safety classifier.

Above: Here, Blender repeats and contradicts itself, forgets, and hallucinates knowledge.
Of course, the FAIR researchers don’t claim to have solved the problem of open-domain conversation. In fact, they outline several of Blender’s major limitations:
- Vocabulary usage: Even the best Blender models tend to generate common phrases too frequently, such as “do you like,” “lot of fun,” and “have any hobbies.”
- Nontrivial repetition: The models often repeat what is said to them. For instance, they’ll say that they had a pet dog if a conversation partner mentions a pet dog, or that they like the same bands as the person they’re speaking with.
- Contradiction and forgetfulness: Blender models contradict themselves, albeit to a lesser degree in the larger models. They also fail to make the logical link that they shouldn’t ask questions they’ve asked before (to avoid the appearance of “forgetting”).
- Knowledge and factual correctness: It’s relatively easy to goad Blender models into making factual errors, particularly when exploring a topic deeply.
- Conversation length and memory: Blender conversations would likely be dull and repetitive over the course of several days or weeks of conversation, the FAIR researchers say — especially considering Blender can’t remember earlier conversations.
- Deeper understanding: The Blender models lack the ability to learn concepts through further conversation, and they have no way of grounding to entities, actions, and experiences in the real world.
Addressing all this would likely require new model architectures, which the FAIR team says it’s exploring. It’s also focused on building stronger classifiers to filter out harmful language in dialogues, as well as techniques to tamp down on gender bias in chatbots generally.
“We’re excited about the progress we’ve made in improving open-domain chatbots,” wrote Facebook in a blog post. “However, building a truly intelligent dialogue agent that can chat like a human remains one of the largest open challenges in AI today … True progress in the field depends on reproducibility — the opportunity to build upon the best technology possible. We believe that releasing models is essential to enable full, reliable insights into their capabilities.”
The pretrained and fine-tuned Blender models with 90 million parameters, 2.7 billion parameters, and 9.4 billion parameters are available on GitHub, along with a script for interacting with the bot (with safety filtering built in). All code for model evaluation and fine-tuning, including the data sets themselves, is available in ParAI.

