Watch all the Transform 2020 sessions on-demand here.
Computer vision systems generally excel at detecting objects but struggle to make sense of the environments in which those objects are used. That’s because they separate observed actions from physical context — even those that do model environments fail to discriminate between elements relevant to actions versus those that aren’t (e.g., a cutting board on the counter versus a random patch of floor).
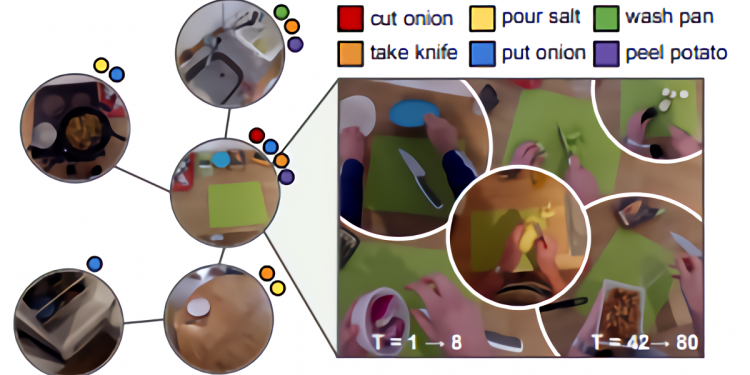
That’s why a team of researchers from the University of Texas and Facebook AI Research investigated in a paper Ego-Topo, a technique that decomposes a space captured in a video into a topological map of activities before organizing the video into a series of visits to different zones. By reorganizing scenes into these “visits” as opposed to a series of footage, they assert, Ego-Topo is able to reason about first-person behavior (e.g., what are the most likely actions a person will do in the future?) and the environment itself (e.g., what are the possible object interactions that are likely in a particular zone, even if not observed there yet?).
“Our … [model] offers advantages over the existing models discussed above … [I]t provides a concise, spatially structured representation[s] of the past, [and unlike] the ‘pure 3D’ approach, our map is defined organically by people’s use of the space.”
Ego-Topo taps an AI model to discover commonly visited places from videos of people actively using a space, and it links frames across time based on (1) the physical spaces they share and (2) the functions afforded by the zone regardless of the physical location. (For example, a dishwasher loaded at the start of a video might be linked to the same dishwasher when unloaded, while a trash can in one kitchen could link to the garbage disposal in another.) A separate set of models leverages the resulting graphs to uncover environment affordances and anticipate future actions in long videos.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.

The linked spaces across multiple zones (e.g., from videos of multiple kitchens) contribute to a consolidated representation of an environment and its functional purpose, such that Ego-Topo susses out which parts of the environment are relevant for human action and how actions at the zones accomplish certain goals. For example, given a kitchen, even if not all parts of the kitchen are visited in every video, Ego-Top can link across different videos to create a combined map of the kitchen that accounts for the persistent physical space. Plus, it’s able to link zones across multiple kitchens to create a consolidated map, revealing how different kitchens relate to each other.
In experiments, the team demonstrated Ego-Topo on two key tasks: inferring likely object interactions in a novel view and anticipating the actions needed to complete a long-term activity. To evaluate its performance, they trained the underlying models on EGTEA Gaze+ (which contains videos of 32 subjects following 7 recipes in a single kitchen, each of which captures a complete dish being prepared) and EPIC-Kitchens (which comprises videos of daily kitchen activities and which isn’t limited to a single recipe or object) and collected across multiple kitchens.
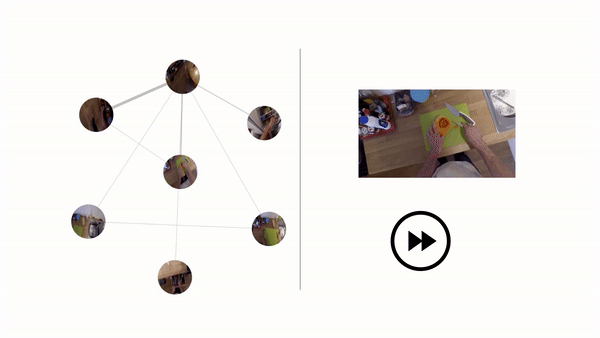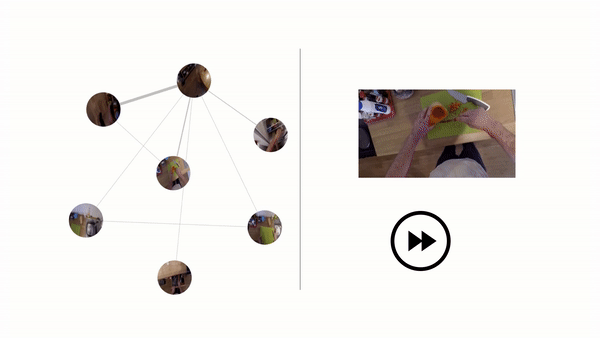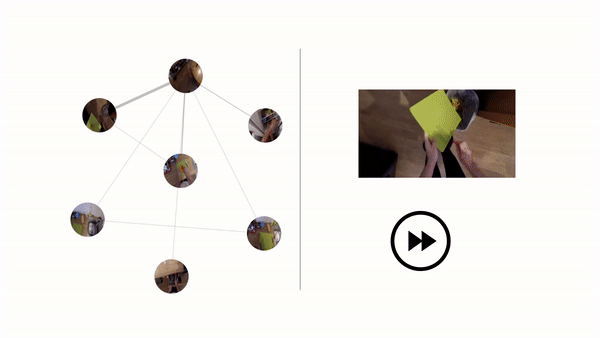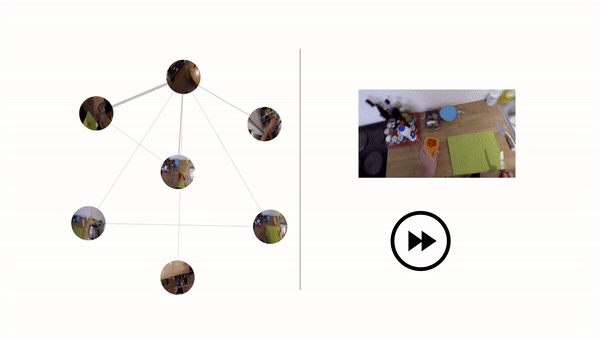
They report that Ego-Topo performed uniformly better across all prediction horizons compared with the baselines, and that it excelled at predicting actions far into the future. Moreover, they say that linking actions to discovered zones in the model’s topological graph resulted in consistent improvements, as did aligning spaces based on function in the consolidated graph — especially for rare classes that were only seen tied to a single location.
“Our approach is best suited to long term activities in [first-person] video where zones are repeatedly visited and used in multiple ways over time. This definition applies broadly to common household and workplace environments (e.g., office, kitchen, retail store, grocery),” wrote the researchers. “These tasks illustrate how a vision system that can successfully reason about scenes’ functionality would contribute to applications in augmented reality (AR) and robotics. For example, an AR system that knows where actions are possible in the environment could interactively guide a person through a tutorial; a mobile robot able to learn from video how people use a zone would be primed to act without extensive exploration.”

