
testsetset
Almost a year ago exactly, DeepMind, the British artificial intelligence (AI) division owned by Google parent company Alphabet, made headlines with preprint research (“Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm”) describing a system — AlphaZero — that could teach itself how to master the game of chess, a Japanese variant of chess called shogi, and the Chinese board game Go. In each case, it beat a world champion, demonstrating a state-of-the-art knack for learning two-person games with perfect information — that is to say, games where any decision is informed of all the events that have previously occurred.
DeepMind’s claims were impressive to be sure, but they hadn’t undergone peer review. That’s changed. DeepMind today announced that, after months of back-and-forth revisions, its work on AlphaZero has been accepted in the journal Science, where it’s made the front page.
“A couple of years ago, our program, AlphaGo, defeated the 18-time world champion Go champion, Lee Sedol, by four games to one. But for us, that was actually the beginning of the journey to build a general-purpose learning system that could learn for itself to play many different games to superhuman level,” David Silver, lead researcher on AlphaZero, told reporters assembled in a conference room at NeurIPS 2018 in Montreal. “AphaZero is the next step in that journey. It learned from scratch to defeat world champion programs in Gi, Chess, and Shogi, started from no knowledge except the game rules.”
The games were chosen both for their complexity and the rich history of prior AI research that’s been conducted about them, Silver explained.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
“Chess … represents what can be achieved by traditional methods of AI when they’ve been pushed to the absolute limit, and so we wanted to see whether we could overturn the traditional approaches that we use a lot handcrafting using a completely principled self-learning approach,” he said. “The reason we chose Shogi is that, in terms of difficulty, it’s one of the few board games aside from Go [that’s] very, very challenging, for even specialized program and computer programs to play. It was only … in the last year or two that there have been any computer programs that have been able to compete with human world champions.”
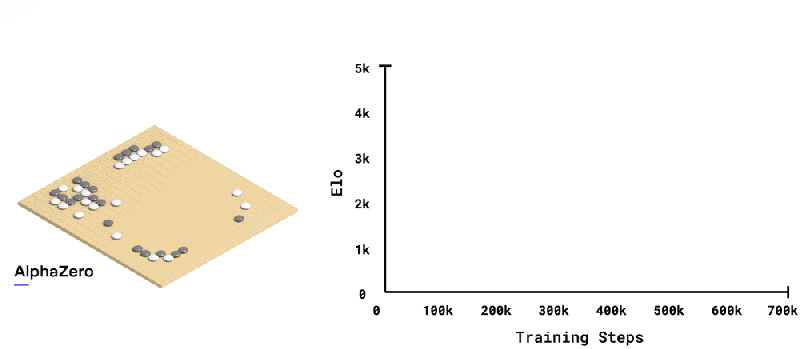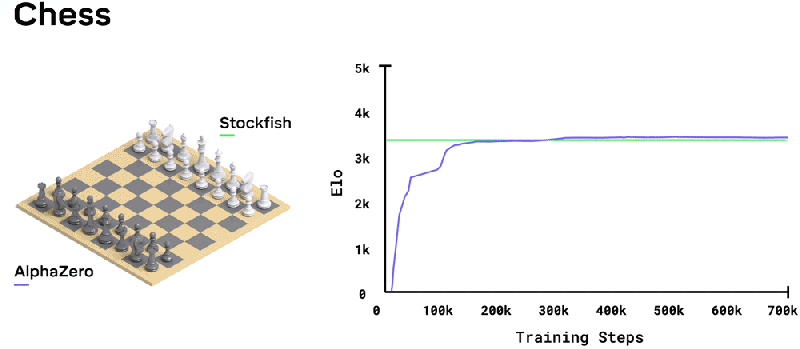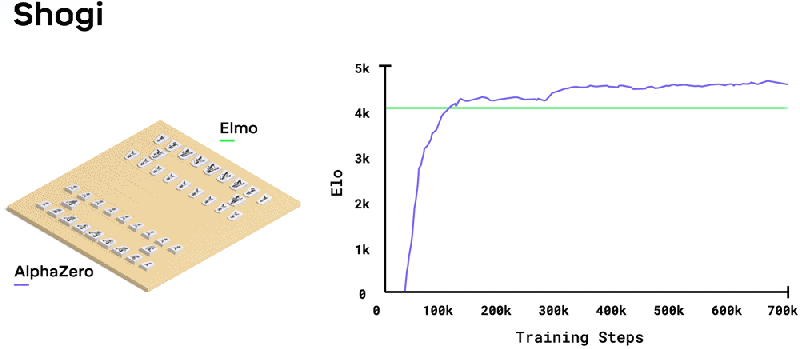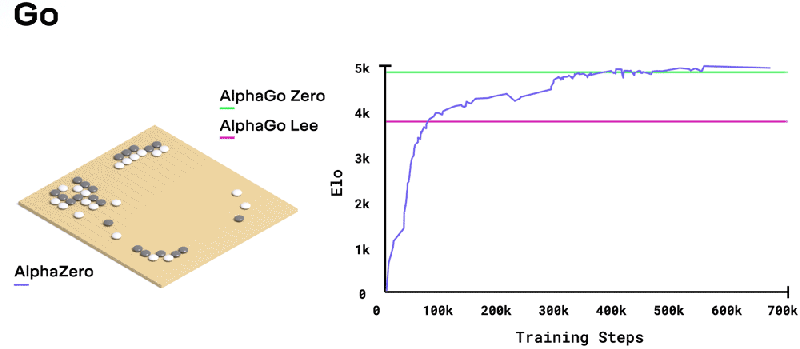
Toward that end, the paper published this week describes how DeepMind outperforms chess- and shogi-playing algorithms such as Stockfish, Elmo, and IBM’s Deep Blue by leveraging a deep neural network — layered mathematical functions that mimic the behavior of neurons in the human brain — rather than handcrafted rules. Its dynamic mode of play results in creative and unconventional strategies that inspired a forthcoming book by two-time British chess champion and Grandmaster Matthew Sadler and women’s international master Natasha Regan, who painstakingly reviewed AlphaZero’s nearly 1,000 chess games.
“Traditional engines are exceptionally strong and make few obvious mistakes, but can drift when faced with positions with no concrete and calculable solution … Impressively, [AlphaZero] manages to impose its style of play across a very wide range of positions and openings,” Sadler said. “It’s precisely in such positions where ‘feeling’, ‘insight’ or ‘intuition’ is required that AlphaZero comes into its own. AlphaZero plays like a human on fire. It’s a very beautiful style.”
For instance, in chess, AlphaZero discovered motifs such as openings (the initial moves of a chess game), king safety (ways in which to protect the king piece), and pawn structure (the configuration of pawn pieces on the chessboard). It tends to swarm around the opponent’s king and to maximize the mobility of its pieces while minimizing those of enemy pieces. And not unlike a human, it’s willing to sacrifice pieces in the pursuit of long-term goals.
Teaching AlphaZero how to play each of the three games required simulating millions of matches against itself in a process known as reinforcement learning, in which a system of rewards and punishments drives an AI agent toward specific goals. AlphaZero played randomly at first, but eventually came to avoid losses by adjusting parameters to favor a certain playstyle.
The total amount of time it took to train AlphaZero varied depending on the game. A minimum of 700,000 training steps (each step representing 4,096 board positions) on systems with 5,000 first-generation tensor processing units (TPUs) and 16 second-generation TPUs — Google-designed application-specific integrated circuits (ASIC) optimized for machine learning — took 9 hours to generate and play games of Chess, and about 12 hours and 13 days for shogi and Go, respectively.
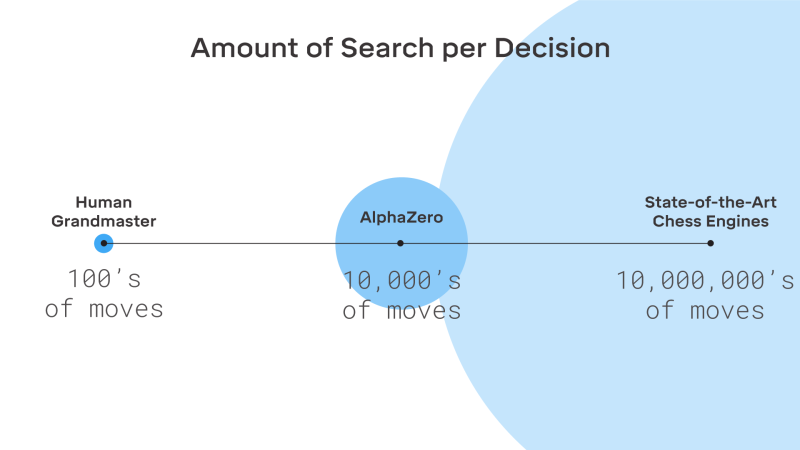
The trained AlphaZero uses a Monte-Carlo Tree Search (MCTS) — a heuristic search algorithm for decision processes — to choose each move. It’s able to complete searches remarkably quickly, Demis Hassabis, CEO and cofounder of DeepMind, told reporters — about 60,000 positions per second in chess compared to Stockfish’s roughly 60 million.
“That’s not as efficient as a human Grandmaster, who probably only looks at about 100 positions. decision,” Hassabis said, “but we’re a thousand times more efficient in terms of the amount of brute force calculation than handcrafted engines.”
To test the fully trained AlphaZero, DeepMind researchers pitted it against the aforementioned Stockfish and Elmo game engines, in addition to its predecessor, AlphaGo Zero. Running on a single machine with 44 processor cores and four of Google’s first-generation TPUs — hardware with roughly the same inference power as a workstation with several Nvidia Titan V graphics processing units (GPUs) — AlphaZero handily won a majority of games within the three-hour-per-match constraints imposed on it.

In chess, out of 1,000 matches against Stockfish, AlphaZero won 155 and lost only 6. Additionally, it came out on top in games that started with common human chess-playing strategies; with games that began from a set of positions used in the 2016 Top Chess Engine Championship (TCEC) tournament; and with games using the latest version of Stockfish — Stockfish 9 — and Stockfish variants configured with World Championship configurations, time controls, and openings.
In shogi, meanwhile, AlphaZero defeated the 2017 CSA world champion version of Elmo 91.2 percent of the time. And in Go against AlphaGo Zero, it won 61 percent of games.
Move sequences from several hundred of AlphaZero’s chess and shogi games have been released alongside the paper, Hassabis said, and already, the chess community is harnessing AlphaZero’s insights to fuel debate on the recent World Chess Championship match between Magnus Carlsen and Fabiano Caruana.
“It was fascinating to see how AlphaZero’s analysis differed from that of top chess engines and even top Grandmaster play,” Regan said. “Having spent many months exploring AlphaZero’s chess games, I feel that my conception and understanding of the game had been altered and enriched. AlphaZero has provided us with a check on everything we as humans have taught ourselves about the game of chess, and it could be a powerful teaching tool for the whole community.”
The endgame isn’t merely superhuman chess programs, of course. The goal is to use learnings from the AlphaZero project to develop systems capable of solving society’s toughest challenges, Hassabis said.
DeepMind is currently involved in several health-related AI projects, including an ongoing trial at the U.S. Department of Veterans Affairs that seeks to predict when patients’ conditions will deteriorate during a hospital stay. Previously, it partnered with the U.K.’s National Health Service to develop an algorithm that could search for early signs of blindness. And in a paper presented at the Medical Image Computing & Computer Assisted Intervention conference earlier this year, DeepMind researchers said they’d developed an AI system capable of segmenting CT scans with “near-human performance.”
More recently, DeepMind’s AlphaFold — an AI system that can predict complicated protein structures — placed first out of 98 competitors in the CASP13 protein-folding competition.
“Alpha Zero is a stepping stone for us all the way to general AI,” Hassabis said. “The reason we test ourselves and all these games is … that [they’re] a very convenient proving ground for us to develop our algorithms … Ultimately, [we’re developing algorithms that can be] translate[ed] into the real world to work on really challenging problems … and help experts in those areas.”

