
testsetset
Convolutional neural networks (CNNs) — layers of functions (neurons) inspired by biological processes in the human visual cortex — are well-suited to tasks like object recognition and facial detection, but improving their accuracy beyond a certain point requires tedious fine-tuning. That’s why scientists at Google’s AI research division are investigating novel models that “scale up” CNNs in a “more structured” manner, which they describe in a paper (“EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks“) published on the preprint server Arxiv.org and an accompanying blog post.
The coauthors claim this family of AI systems, dubbed EfficientNets, surpasses state-of-the-art accuracy on common corpora with up to 10 times better efficiency.
“The conventional practice for model scaling is to arbitrarily increase the CNN depth or width, or to use larger input image resolution for training and evaluation,” wrote staff software engineer Mingxing Tan and Google AI principal scientist Quoc V. Le. “Unlike conventional approaches that arbitrarily scale network dimensions, such as width, depth, and resolution, our method uniformly scales each dimension with a fixed set of scaling coefficients.”
So how’s it work? First, a grid search is conducted to identify the relationship among the baseline network’s different scaling dimensions under a fixed resource constraint (for example, two times more floating point computations, or FLOPS). This determines the appropriate scaling coefficient for each dimension, and these coefficients are applied to scale up the baseline network to the desired model size or computational budget.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
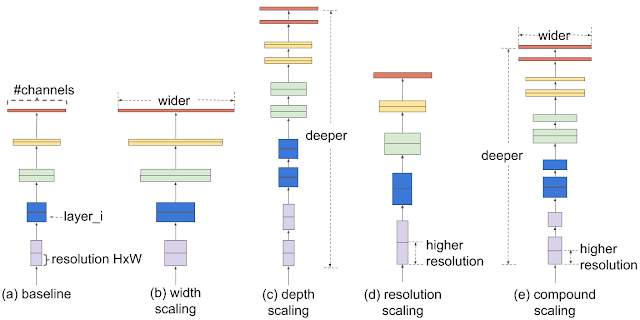
Above: Comparison of different scaling methods.
To further improve performance, the researchers advocate a new baseline network — mobile inverted bottleneck convolution (MBConv) — that serves as the seed for the EfficientNets model family.
In tests, EfficientNets demonstrated both higher accuracy and better efficiency over existing CNNs, reducing parameter size and FLOPS by an order of magnitude. One of the models — EfficientNet-B7, which is 8.4 times smaller and 6.1 times faster than the high-performance CNN Gpipe — reached 84.4% and 97.1% top-1 and top-5 accuracy on ImageNet, respectively. And compared with the popular ResNet-50, another EfficientNet — EfficientNet-B4 — used similar FLOPS while improving the top-1 accuracy from ResNet-50’s 76.3% to 82.6%.
EfficientNets performed well on other data sets, too, achieving state-of-the-art accuracy in five out of the eight including CIFAR-100 (91.7% accuracy) and Flowers (98.8%) with 21 fewer parameters.
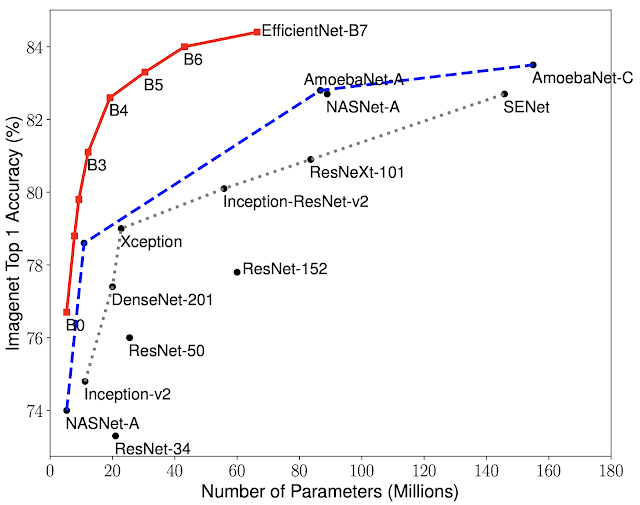
Above: Model size versus accuracy comparison.
The source code and training scripts for Google’s cloud-hosted tensor processing units (TPU) are freely available on GitHub. “By providing significant improvements to model efficiency, we expect EfficientNets could potentially serve as a new foundation for future computer vision tasks,” wrote Tan and Le.

