testsetset
To determine whether an AI system is maintaining fairness in its predictions, data scientists need an understanding of models’ short- and long-term effects, which might be informed by disparities in error metrics on a number of static data sets. In some cases, it’s necessary to consider the context in which the AI system operates, in addition to error metrics, which is why Google researchers developed ML-fairness-gym, a set of components for evaluating algorithmic fairness in simulated social environments.
ML-fairness-gym — which was published in open source on GitHub this week — can be used to research the long-term effects of automated systems by simulating decision-making using OpenAI’s Gym framework. AI-controlled agents interact with digital environments in a loop, and at each step an agent chooses an action that affects the environment’s state. The environment then reveals an observation that the agent uses to inform its next actions so that the environment models the system and dynamics of a problem and the observations serve as data.
For instance, given the classic lending problem, where the probability that groups of applicants pay back a bank loan is a function of their credit score, the bank acts as the agent and receives applicants, their scores, and their membership in the form of environmental observations. It makes a decision — accepting or rejecting a loan — and the environment models whether the applicant successfully repays or defaults and then adjusts their credit score accordingly. Throughout, ML-fairness-gym simulates outcomes so that the fairness of the bank’s policies can be assessed.
ML-fairness-gym in this way cleverly avoids the pitfalls of static data set analysis. If the test sets (i.e., corpora used to evaluate model performance) in classical fairness evaluations are generated from existing systems, they may be incomplete or reflect the biases inherent to those systems. Furthermore, the actions informed by the output of AI systems can have effects that might influence their future input.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
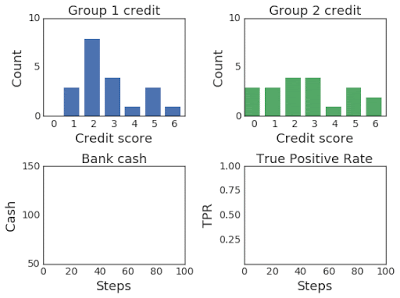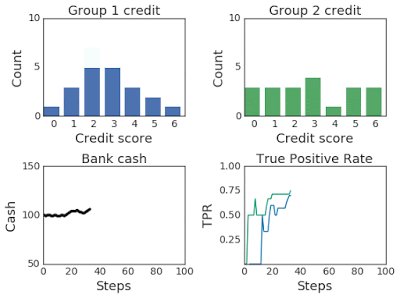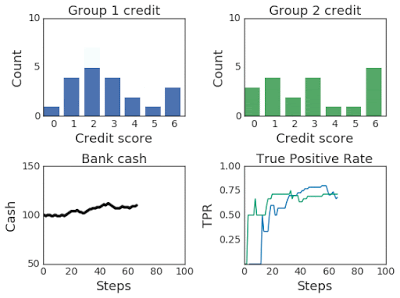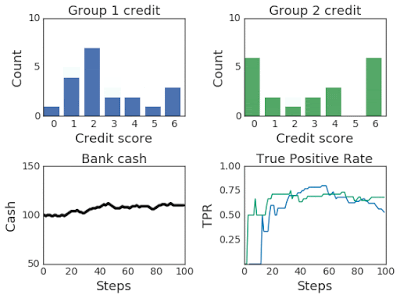
Above: In the lending problem scenario, this graph illustrates changing credit score distributions for two groups over 100 steps of simulation.
“We created the ML-fairness-gym framework to help ML practitioners bring simulation-based analysis to their ML systems, an approach that has proven effective in many fields for analyzing dynamic systems, where closed form analysis is difficult,” wrote Google Research software engineer Hansa Srinivasan in a blog post.
Several environments that simulate the repercussions of different automated decisions are available, including for college admissions, lending, attention allocation, and infectious disease. (The ML-fairness-gym team cautions that the environments aren’t meant to be hyper-realistic and that best-performing policies won’t necessarily translate to the real world.) Each has a set of experiments corresponding to published papers, which are meant to provide examples of ways ML-fairness-gym can be used to investigate outcomes.
The researchers recommend using ML-fairness-gym to explore phenomena like censoring in the observation mechanism, errors from the learning algorithm, and interactions between the decision policy and the environment. The simulations allow for the auditing of agents to assess the fairness of decision policies based on observed data, which can motivate data collection policies. And they can be used in concert with reinforcement learning algorithms — which spur on agents with rewards — to derive new policies with potentially novel fairness properties.
In recent months, a number of corporations, government agencies, and independent researchers have attempted to tackle the “black box” problem in AI — the opaqueness of some AI systems — with varying degrees of success.
“Machine learning systems have been increasingly deployed to aid in high-impact decision-making, such as determining criminal sentencing, child welfare assessments, who receives medical attention, and many other settings,” continued Srinivasan. “We’re excited about the potential of the ML-fairness-gym to help other researchers and machine learning developers better understand the effects that machine learning algorithms have on our society, and to inform the development of more responsible and fair machine learning systems.”
In 2017, the U.S. Defense Advanced Research Projects Agency launched DARPA XAI, a program that aims to produce “glass box” models that can be easily understood without sacrificing performance. In August, scientists from IBM proposed a “factsheet” for AI that would provide information about a model’s vulnerabilities, bias, susceptibility to adversarial attacks, and other characteristics. A recent Boston University study proposed a framework to improve AI fairness. And Microsoft, IBM, Accenture, and Facebook have developed automated tools to detect and mitigate bias in AI algorithms.

