
By any measure, we’ve entered the age of machine learning and artificial intelligence. The confluence of massive data, cheap storage, elastic compute, and algorithmic advances, particularly in deep learning, has given rise to applications that previously were confined to the pages of science fiction novels.
Machines now surpass humans in complex strategy games, to say nothing of image recognition, speech transcription, and other advances that begin to complicate our assumptions about what is and isn’t uniquely human. Voice-based personal assistants are commonplace, and fully autonomous vehicles seem just around the bend.
Given these recent advances, much of the dialogue around ML/AI has centered disproportionately, albeit understandably, on breakthroughs in algorithms and their applications. Notably absent in the discussion has been any mention of the infrastructure underlying these intelligent systems.
Just as in the earliest days of computing, when one needed to be expert in assembly language, compilers, and operating systems to develop a simple application, so today you need an army of stats and distributed systems PhDs to build and deploy AI at scale. The abstractions and tooling necessary to make ML/AI usable are the missing link. The upshot is that ML/AI remains a limited and expensive discipline reserved for only a few elite engineering organizations.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
Ultimately, this relates to a lag in the evolution of infrastructure, which to date is far outpaced by innovation in machine learning techniques. Put simply, the systems and tooling that helped usher in the current era of practical machine learning are ill-suited to power future generations of the intelligent applications they spawned.
Going forward, an entirely new toolchain is necessary to unlock the potential of ML/AI, to make it operational and usable — let alone approachable — for developers and enterprises. It stands to reason, then, that the next great opportunity in infrastructure will be to provide the building blocks for systems of intelligence.
From Infrastructure 1.0 to 2.0 and beyond
Applications and infrastructure evolve in lock-step.
Advances in hardware or systems software cascade up the stack, enabling new breeds of applications. Those apps mature and come to strain their underlying resources, catalyzing a subsequent cycle of innovation at the infrastructure layer. The rise of better, faster, cheaper building blocks invariably leads to applications that deliver previously unforetold experiences to end users. This ebb and flow forms the contours of a technical legacy that stretches from punch-cards to Pong to PowerPoint to Pinterest.
The commercial internet that came of age in the late ’90s and early ’00s owes its existence to the x86 instruction set (Intel), the standardized operating system (Microsoft), the relational database (Oracle), Ethernet networking (Cisco), and networked data storage (EMC). Amazon, eBay, Yahoo, and even the earliest iterations of Google and Facebook were built on this backbone we call Infrastructure 1.0.
Yet as the web matured, growing from 16 million users in 1995 to over 3 billion by the end of 2015, the scale and performance requirements of applications morphed. It was no longer feasible, much less economical, for web-scale giants to run their businesses on the backs of technologies developed during and for the client-server era.
Instead, these companies looked inward. Coupling superior technical expertise with parallel computing research from academia, the Googles, Facebooks, and Amazons of the world defined a new class of infrastructure that was scale-out, programmable, (often) open source, and commodity. This category of technologies — Linux, KVM, Xen, Docker, Kubernetes, Mesos, MySQL, MongoDB, Kafka, Hadoop, Spark, and many others — defined the cloud era. My colleague Sunil Dhaliwal described this shift as Infrastructure 2.0.
Ultimately, the technologies of this generation were purpose-built for scaling the internet to billions of end users and storing information captured from those users efficiently. In doing so, the innovations of Infrastructure 2.0 catalyzed a dramatic acceleration in data growth. Combined with virtually endless parallel compute and algorithmic advances, the stage was set for today’s era of practical machine learning.
Infrastructure 3.0: Toward intelligent systems
Infrastructure 2.0 was ultimately concerned with the question “How do we connect the world?” Today’s generation of technology rephrases the question to ask, “How do we make sense of the world?”
This distinction — connectivity vs. cognition — is what makes ML/AI radically different from software of previous generations. The computational challenge of coding cognition is that it inverts the classical programming paradigm. Whereas in traditional applications, logic is hand-coded to perform a specific task, in ML/AI, training algorithms infer logic from troves of data. That logic is then implemented to make decisions and predictions about the world.
The result is an application that is “smart,” but exceptionally data-intensive and computationally expensive. These properties make ML/AI a poor fit for the multipurpose, generic Von Neumann computing paradigm of the past seventy-plus years. Instead, ML/AI represents a foundational new architecture that necessitates a rethink of infrastructure, tooling, and development practices.
To date, however, the preponderance of research and innovation in ML/AI has been dedicated to new algorithms, model training techniques, and optimizations. The irony is that only a tiny fraction of the code in ML/AI systems is devoted to learning or prediction. Rather, the majority of complexity manifests in data preparation, feature engineering, and operationalizing the distributed systems infrastructure necessary to perform these tasks at scale.
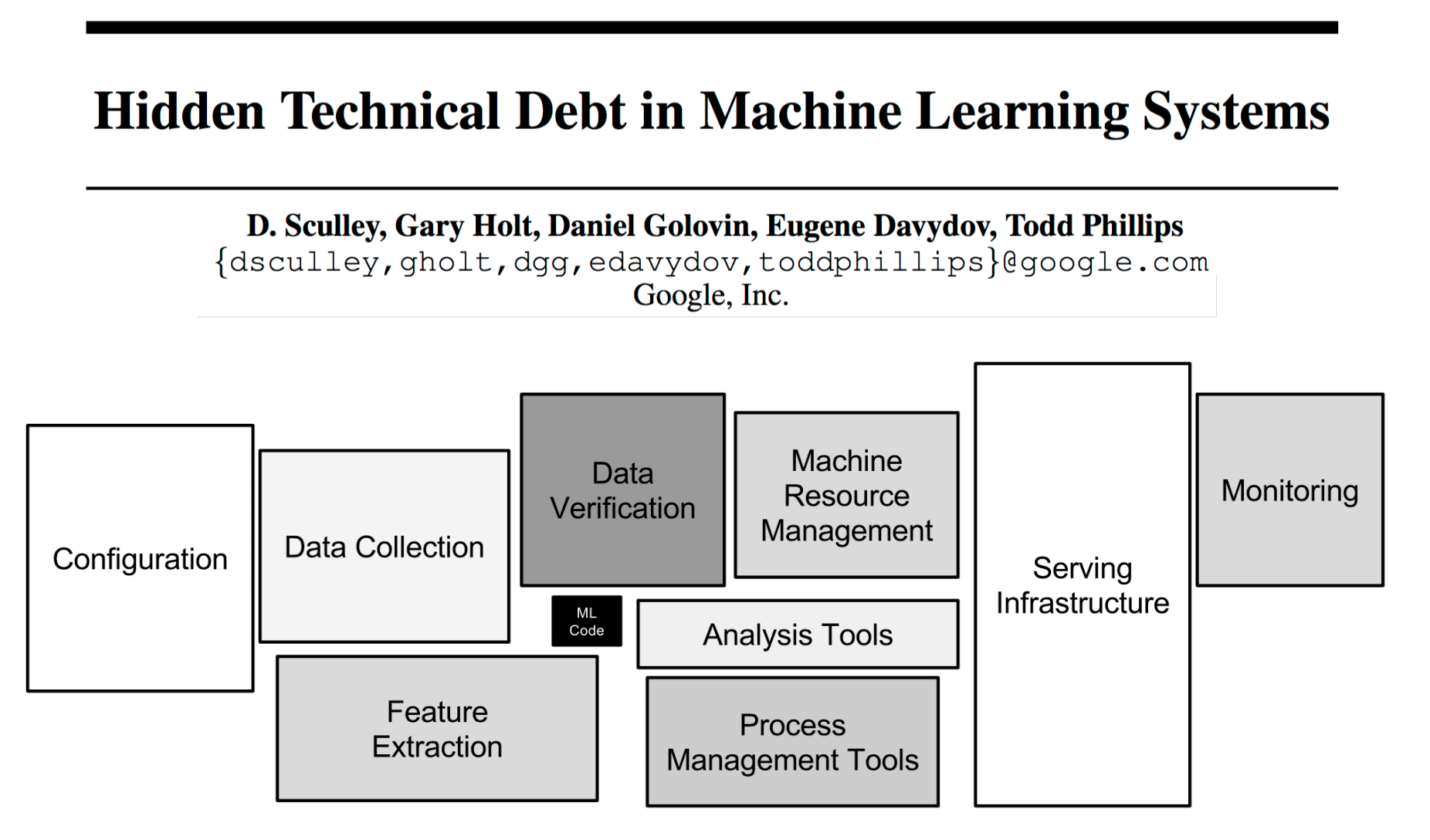
Building and deploying ML/AI successfully requires a complex, carefully coordinated workflow involving multiple discrete systems. First, data needs to be ingested, cleaned, and labeled. Then, the appropriate properties, known as features, upon which prediction is based must be determined. Finally, developers must train models and validate, serve, and continuously optimize them. From start to finish, this process may take many months, even for the most technically proficient organizations.

For ML/AI to reach its full potential, it must graduate from the academic discipline it is today into an engineering one. What that means in practice is that there needs to be new abstractions, interfaces, systems, and tooling to make developing and deploying intelligent applications easy for developers.
These requisite evolutions are not tiny shifts in abstraction or incremental process improvements. Rather, they are disruptive, foundational changes in both systems design and development workflow.
Correspondingly, at every layer of the stack, we’re beginning to see new platforms and tools emerge that are optimized for the ML/AI paradigm. The opportunities are abundant:
- Specialized hardware with many computing cores and high bandwidth memory (HBM) very close to the processor die. These chips are optimized for highly parallel, numerical computation that is necessary to perform the rapid, low-precision, floating-point math intrinsic to neural networks.
- Systems software with hardware-efficient implementation that compiles computation down to the transistor level.
- Distributed computing frameworks, for both training and inference, that can efficiently scale out model operations across multiple nodes.
- Data and metadata management systems to enable reliable, uniform, and reproducible pipelines for creating and managing both training and prediction data.
- Extremely low-latency serving infrastructure that enables machines to rapidly execute intelligent actions based on real-time data and context.
- Model interpretation, QA, debugging, and observability tooling to monitor, introspect, tune, and optimize models and applications at scale.
- End-to-end platforms that encapsulate the entire ML/AI workflow and abstract away complexity from end users. Examples include in-house systems like Uber’s Michelangelo and Facebook’s FBLearner and commercial offerings like Determined AI*.
Just as the past decade witnessed the emergence of the cloud-native stack, so too over the next several years we expect a vast infrastructure and tooling ecosystem to coalesce around ML/AI.
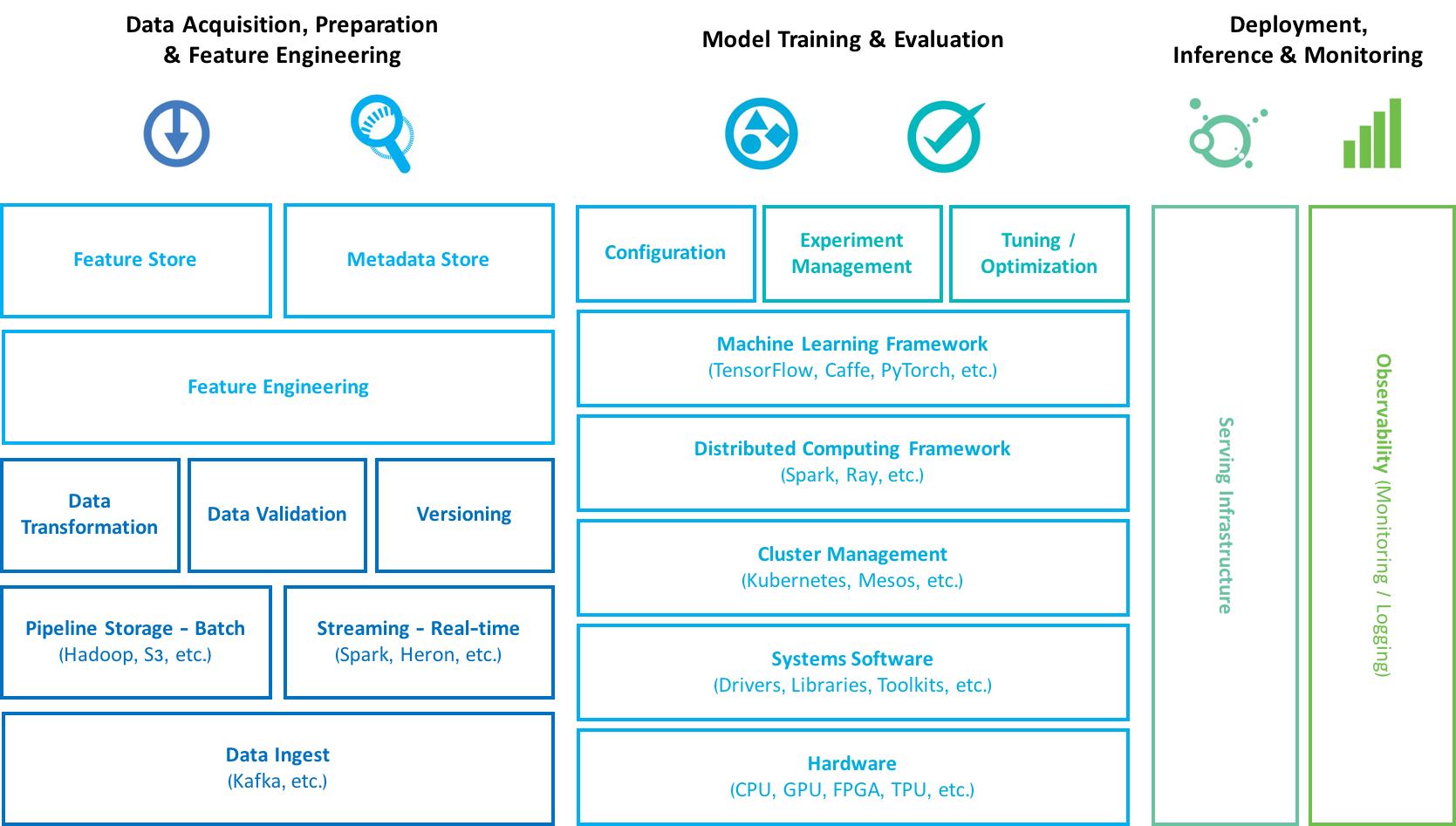
Amplify Partners: Preliminary Infrastructure 3.0 Stack
Collectively, the innovations of this epoch — Infrastructure 3.0 — will be about unlocking the potential of ML/AI and providing the building blocks for intelligent systems. As with previous generations, there will be new projects, platforms, and companies that emerge and challenge the current incumbency. The arms dealers for this imminent ML/AI revolution promise to be the infrastructure giants of tomorrow.
Thank you to Evan Sparks of Determined AI, Peter Bailis of Stanford’s Dawn, Joey Gonzalez and Robert Nishihara of UC Berkeley’s RiseLab, and my colleagues at Amplify Partners for their perspective and input.
*Amplify Partners is an investor in Determined AI.
Lenny Pruss is a partner at Amplify Partners, where he focuses on distributed systems and infrastructure, developer tools, and security.

