
Watch all the Transform 2020 sessions on-demand here.
Microsoft AI & Research today shared what it calls the largest Transformer-based language generation model ever and open-sourced a deep learning library named DeepSpeed to make distributed training of large models easier.
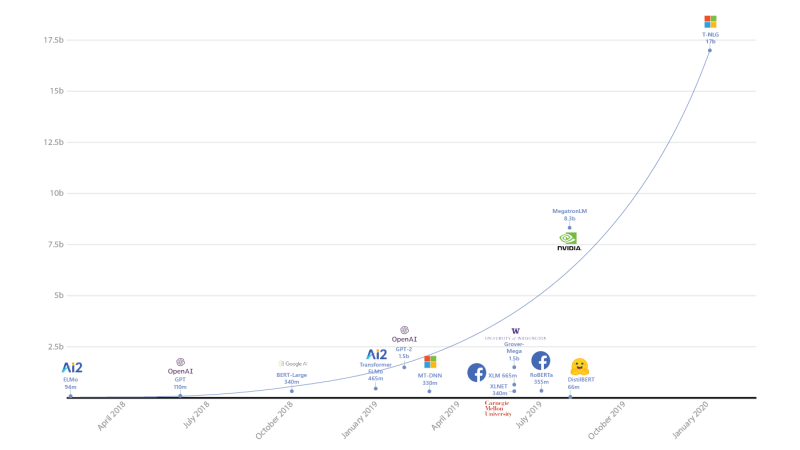
At 17 billion parameters, Turing NLG is twice the size of Nvidia’s Megatron, now the second biggest Transformer model, and includes 10 times as many parameters as OpenAI’s GPT-2. Turing NLG achieves state-of-the-art results on a range of NLP tasks.
Like Google’s Meena and initially with GPT-2, at first Turing NLG may only be shared in private demos.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
Language generation models with the Transformer architecture predict the word that comes next. They can be used to write stories, generate answers in complete sentences, and summarize text.
Experts from across the AI field told VentureBeat 2019 was a seminal year for NLP models using the Transformer architecture, an approach that led to advances in language generation and GLUE benchmark leaders like Facebook’s RoBERTa, Google’s XLNet, and Microsoft’s MT-DNN.
Also today: Microsoft open-sourced DeepSpeed, a deep learning library that’s optimized for developers to deliver low latency, high throughput inference.
DeepSpeed contains the Zero Redundancy Optimizer (ZeRO) for training models with 100 million parameters or more at scale, which Microsoft used to train Turing NLG.
“Beyond saving our users time by summarizing documents and emails, T-NLG can enhance experiences with the Microsoft Office suite by offering writing assistance to authors and answering questions that readers may ask about a document,” Microsoft AI Research applied scientist Corby Rosset wrote in a blog post today.
Both DeepSpeed and ZeRO are being made available to developers and machine learning practitioners, because training large networks like those that utilize the Transformer architecture can be expensive and can encounter issues at scale.
In other natural language AI news, Google’s DeepMind today released the Compressive Transformer long-range memory model and PG19, a benchmark for analyzing the performance of book-length language generation.

