
Watch all the Transform 2020 sessions on-demand here.
Animating the lips and mouths of computer-generated characters to match those of voiceover actors isn’t a walk in the park, even with the aid of vision-based performance capture software like CrazyTalk. It isn’t easy straddling the line between uncanny valley and the overly cartoonish, particularly when the target dialogue’s run length exceeds tens or even hundreds of hours.
Fortunately for animators, researchers at Zhejiang University and NetEase’s Fuxi AI Lab have developed an end-to-end machine learning system — Audio2Face — that can generate real-time facial animation from audio alone, taking into account both pitch and speaking style. They describe their work in a newly published paper (“Audio2Face: Generating Speech/Face Animation From Single Audio with Attention-Based Bidirectional LSTM Networks“) on the preprint server Arxiv.org.
“Our approach is designed exclusively on the basis of audio track, without any other auxiliary input, such as images, which makes it increasingly challenging as we attempt to regress visual space from vocal sequence,” explained the coathors. “Another challenge is that facial motions involve multifold activations of correlated regions on the geometric surface of [a] face, which makes it difficult to generate lifelike and consistent facial deformations for avatars.”
The team sought to architect a system that met several criteria, namely “lifelikeness” (the generated animations had to reflect speaking patterns in visible speech motion) and low latency (the system had to be capable of nearly real-time animation). They also attempted to make it generalizable, such that it could retarget generated animations to other 3D characters.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
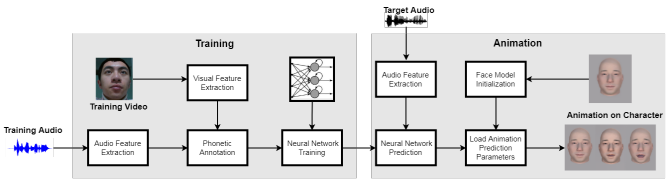
Above: A visual diagram of the team’s AI system.
Their approach involved extracting handcrafted, high-level acoustic features — specifically mel-frequency cepstrum coefficients (MFC), or representations of the short-term power spectrum of a sound — from raw input audio. Then depth cameras, in tandem with the mocap tool Faceshift, were used to capture voice actors’ facial movements and compile a training set, after which the researchers built 3D cartoon face models with parameters (51 in total) that controlled different parts of the face (for example, the eyebrows, eyes, lips, and jaw). Lastly, they leveraged the aforementioned AI system to map audio context to the parameters, producing lip and facial movements.
With a training corpus containing two 60-minute, 30-frame-per-second videos of a female and male actor reading lines from a script and 1,470 audio samples for each corresponding video frame (for a total of 2,496 dimensions per frame), the team reports that the machine learning model’s output was “quite plausible” compared with the ground truth. It managed to reproduce accurate face shapes on test audio, and it consistently retargeted “well” to different characters. Moreover, the AI system took only 0.68 milliseconds on average to extract features from a given audio window.
The team notes that the AI couldn’t follow actors’ blink patterns, mainly because blinks aren’t closely correlated with speech. But they say that, broadly speaking, the framework might lay the groundwork for adaptable, extensible audio-to-facial-animation techniques that work with virtually all speakers and languages. “Evaluation results show that our method could not only generate accurate lip movements from audio, but also successfully regress the speaker’s time-varying facial movements,” they wrote.

