
Facebook CEO Mark Zuckerberg often asserts that AI will substantially cut down on the amount of abuse perpetrated by millions of ill-meaning Facebook users. Today at the company’s annual F8 developer conference in San Francisco, CTO Mike Schroepfer detailed the progress its teams have made toward that ambitious goal.
“The challenges we are facing range from things like election interference to misinformation to hate speech,” said Schroepfer. “We have to dedicate ourselves to getting into the details and working these problems, day after day, month after month, year after year.”
In the course of a single quarter, Schroepfer says that Facebook takes down over a billion spammy accounts, over 700 million fake accounts, and tens of millions of pieces of content containing nudity and violence. AI is a top source of reporting across all of those categories, he says.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
A concrete example of Facebook’s AI in production is a new “nearest neighbor” algorithm that’s 8.5 times faster at spotting illicit photos than the previous version. It complements a system that learns a deep graph embedding of all the nodes in Facebook’s Graph — the collection of data, stories, ads, and photos on the network — to find abusive accounts and pages that might be related to each other.
Another example is a language-agnostic AI model trained on 93 languages across 30 dialect families; it’s used in tandem with other classifiers to tackle multiple language problems at once. And on the video side of the equation, Facebook says its salient sampler model — which quickly scans through the video and processes “important” parts of uploaded clips — enables it to recognize more than 10,000 different actions in 65 million videos.
In fact, on a popular benchmark containing 300,000 videos and 400 actions, Facebook says its computer vision stack can classify video with 82.8% accuracy, with a reduction in error rate compared with the previous leading model of 25%. “I want to take a step back and say, even with these improvements, when we see violent videos that evade our systems, it is clear that video understanding is in its infancy,” said Facebook’s director of AI Manohar Paluri. “[But systems like these] allow us to proactively identify problematic content today.”

Facebook is broadly moving toward an AI training technique called self-supervised learning, in which unlabeled data is used in conjunction with small amounts of labeled data to produce an improvement in learning accuracy. In one experiment, its researchers were able to train a language understanding model that made more precise predictions with just 80 hours of data compared with 12,000 hours of manually labeled data.
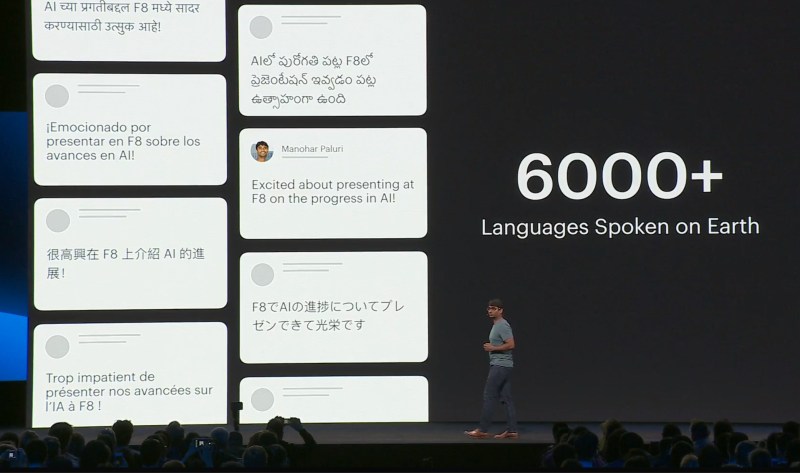
Paluri says that AI models like it are being used to protect the integrity of elections in India, a country where people speak 22 different languages and write in 13 different scripts. “This technique of self-supervision is working across multiple modalities, text, language, computer vision video, and speech,” he said. “It’s a several orders of magnitude reduction in work.”
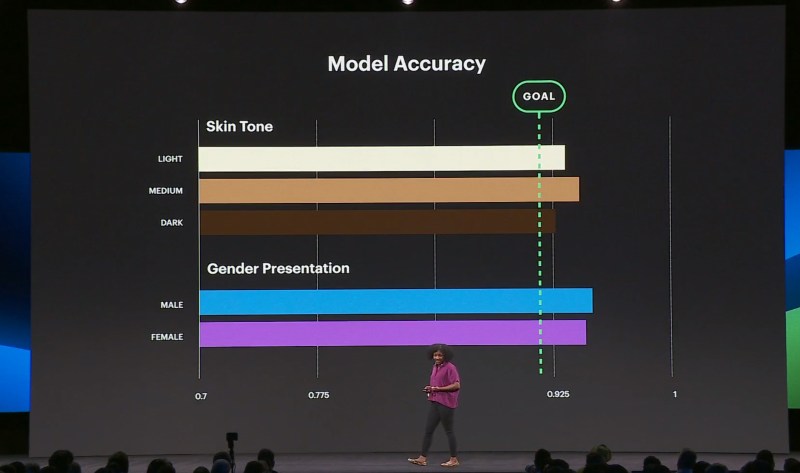
On the subject of fairness and bias mitigation, Joaquin Quiñonero Candela, Facebook’s director of applied machine learning, said that Facebook is using techniques like miscalibration to detect and address algorithmic unfairness. For instance, it’s studied how the network’s civic content classifier — which detects how likely it is that a text snippet concerns civic issues — comes to different conclusions depending on the language used.
One calibration approach involves setting what Candela calls a “decision threshold” across groups; if a threshold is 40% for an abuse-spotting AI, that algorithm will flag content with a score exceeding 40%, for instance. Scores fluctuate across data sets for a variety of reasons, Candela says, and it’s up to Facebook researchers to account for variances to attempt to reach parity.
In some cases, entirely new data sets must be created. Lade Obamehinti, Facebook lead of AR/VR software, said that members of the Oculus team designed and collected corpora for hand-tracking models that had various skin tones under different lighting conditions. In the future, they plan to build voice recognition models for Oculus-branded headsets that contain representative samples across the dimensions of dialect, age, and gender.
“This is about building the kind of future that we want to live in. We’ve learned a lot of really hard lessons that have fundamentally changed the way we develop and build new technologies,” said Schroepfer. “[They’ve] made us realize the deep responsibility we have to understand not just all the amazing good that can come from new technology, but the bad, the unintended consequences, and the ways in which people may abuse those new technologies.”

