testsetset
Software’s biggest advantage is that innovations can be rapidly adopted. But that’s also its biggest downfall: It’s incredibly difficult for everyone to move on after that software is no longer deemed safe. SHA-1 is the latest example in a long list of technologies that needs to be abandoned ASAP.
Cryptographic hash functions are used to encrypt traffic and protect the contents of online communications, to locate data records in hash tables, to build caches for large data sets, to find duplicate records, to manage code repositories, and a variety of other uses cases. Whether it’s validating an update or a credit card transaction, chances are SHA-1 is still in use.
Browsers and websites use hash functions by creating a unique fingerprint and digitally signing each chunk of data to prove that a message has not been altered or tampered with when it passes through various servers. When the Certificate Authority and Browser Forum published their Baseline Requirements for SSL in 2011, the SHA-1 cryptographic hash algorithm was essentially deprecated. They identified security weaknesses in SHA-1 and recommended that all certificate authorities (CAs) transition away from SHA-1 based signatures, with a full sunset date of January 1, 2016. The U.S. National Institute of Standards and Technology banned the use of SHA-1 by U.S. federal agencies back in 2010.
Unfortunately, SHA-1 is still in use today. This is despite years of warnings from network security experts saying SHA-1 is becoming easier and easier to hack due to consistent advancements in computing technology.
June 5th: The AI Audit in NYC
Join us next week in NYC to engage with top executive leaders, delving into strategies for auditing AI models to ensure fairness, optimal performance, and ethical compliance across diverse organizations. Secure your attendance for this exclusive invite-only event.
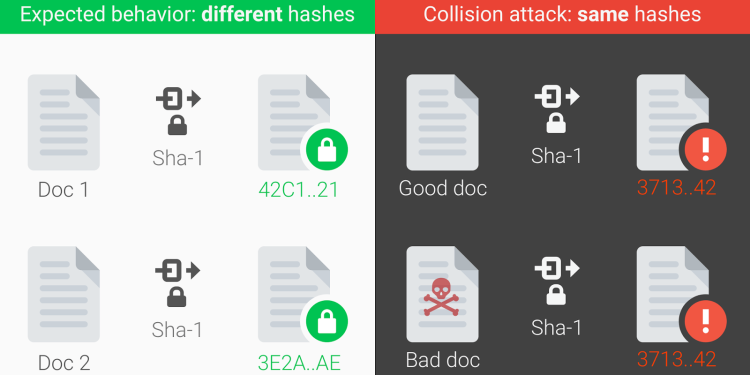
Useful hash functions tend to be collision-resistant, which means that it is very hard to find two pieces of data that will generate the same hash value, in part accomplished by generating very large hash values (SHA-1 generates 160-bit values). As computational power increases and as attacks on the mathematical underpinnings improve, collision resistance eventually shatters.
After two years of research by the CWI Institute in Amsterdam and Google, the duo this week announced the first SHA-1 collision. In short, they proved it is possible for an attacker to craft a collision that deceives systems relying on SHA-1 into accepting a malicious file in place of its safe counterpart.
Google created a PDF prefix specifically crafted for generating two documents with arbitrary distinct visual contents, but that would hash to the same SHA-1 digest. The company used its cloud infrastructure to compute the collision:
- 9 quintillion (9,223,372,036,854,775,808) SHA1 computations in total
- 6,500 years of CPU computation to complete the attack first phase
- 110 years of GPU computation to complete the second phase
That might seem impractical, but it is more than 100,000 times faster than a brute force attack on SHA-1. Google released the two PDFs that have identical SHA-1 hashes but different content. Following its own vulnerability disclosure policy, the company will wait 90 days before releasing code that allows anyone to create a pair of PDFs that hash to the same SHA-1 sum.
Do not wait 90 days. Ditch SHA-1 now.
ProBeat is a column in which Emil rants about whatever crosses him that week.
